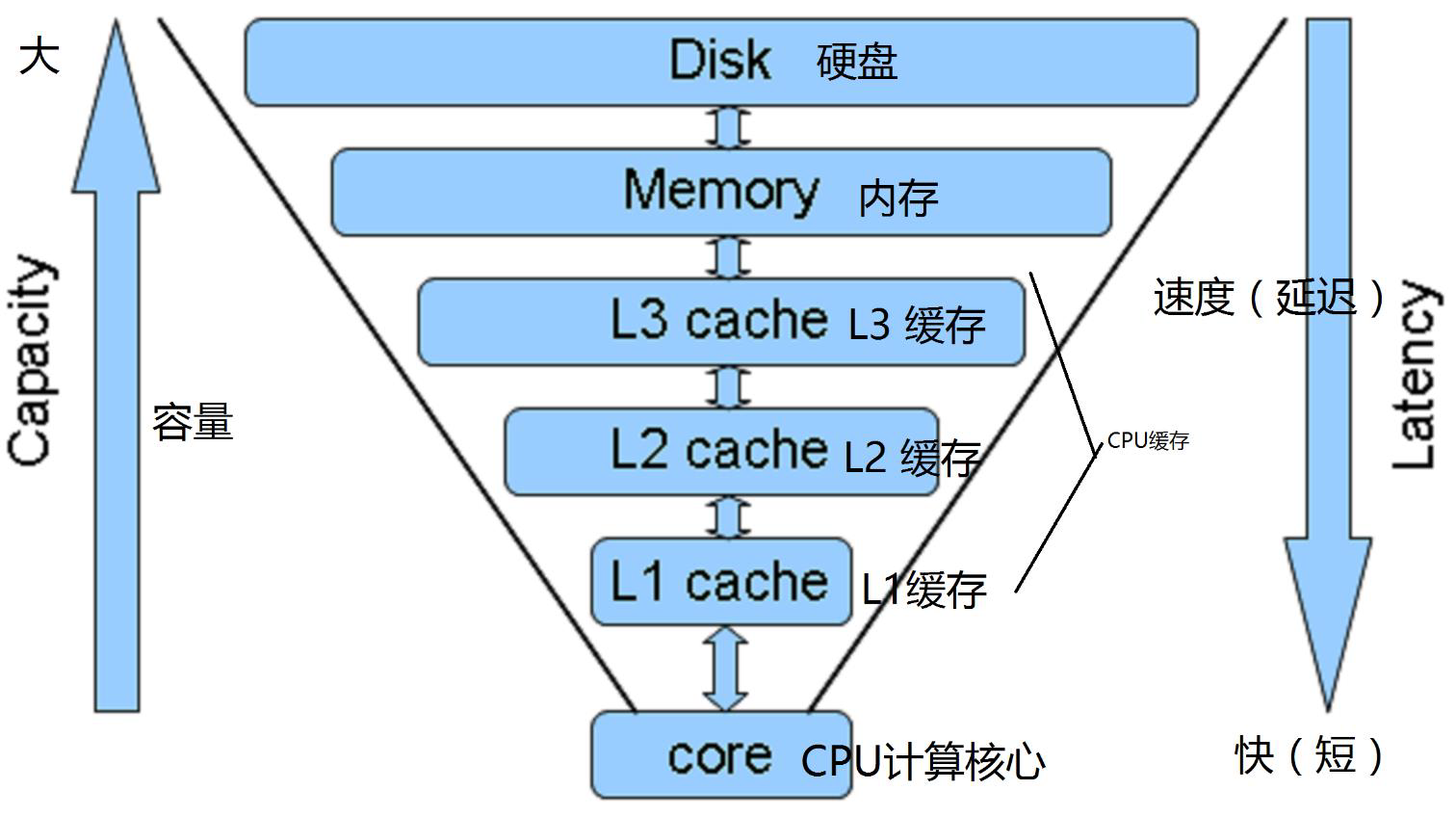
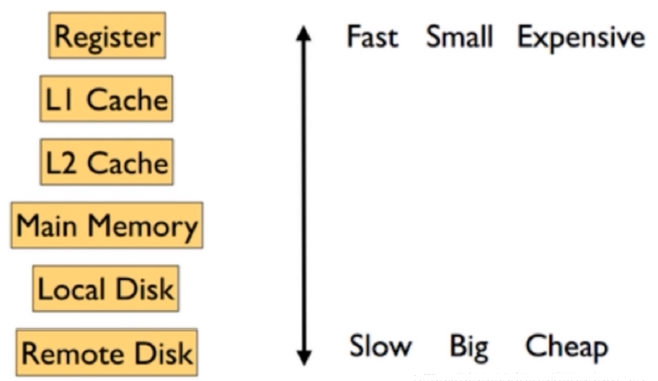
缓存的概念
缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较快的一方起到一个加速访问速度较慢的一方的作用
比如 CPU 的一级、二级缓存是保存了 CPU 最近经常访问的数据,内存是保存 CPU 经常访问硬盘的数据,而且硬盘也有大小不一的缓存,甚至是物理服务器的 raid 卡有也缓存
为了起到加速 CPU 访问硬盘数据的目的,因为 CPU 的速度太快了, CPU 需要的数据硬盘往往不能在短时间内满足 CPU 的需求,
因此 PCU 缓存、内存、 Raid 卡以及硬盘缓存就在一定程度上满足了 CPU 的数据需求,即 CPU 从缓存读取数据可以大幅提高 CPU 的工作效率。
系统缓存
buffer 与 cache
buffer:缓冲也叫写缓冲,一般用于写操作,可以将数据先写入内存再写入磁盘,buffer 一般用于写缓冲,用于解决不同介质的速度不一致的缓冲,先将数据临时写入到里自己最近的地方,以提高写入速度,CPU 会把数据先写到内存的磁盘缓冲区,然后就认为数据已经写入完成看,然后由内核在后续的时间再写入磁盘,所以服务器突然断电会丢失内存中的部分数据。
cache:缓存也叫读缓存,一般用于读操作,CPU 读文件从内存读,如果内存没有就先从硬盘读到内存再读到 CPU,将需要频繁读取的数据放在里自己最近的缓存区域,下次读取的时候即可快速读取。
cache 的保存位置
- 客户端:浏览器
- 内存:本地服务器、远程服务器
- 硬盘:本机硬盘、远程服务器硬盘
cache 的特性
- 自动过期:给缓存的数据加上有效时间,超出时间后自动过期删除
- 过期时间:强制过期,源网站更新图片后 CDN 是不会更新的,需要强制使图片缓存过期
- 命中率:即缓存的读取命中率
用户层缓存
DNS 缓存
- 默认为 60 秒,即 60 秒之内再访问同一个域名就不再进行 DNS 解析
- 查看 chrome 浏览器的 DNS 缓存:chrome://net-internals/#dns
- DNS 预获取,仅在HTML5中支持,当一个页面中包含多个域名的时候浏览器会先尝试解析域名并进行缓存,之后再使用的时候即可直接使用不需要再进行DNS 解析
浏览器缓存过期机制
最后修改时间
系统调用会获取文件的最后修改时间,如果没有发生变化就返回给浏览器304 的状态码,表示没有发生变化,然后浏览器就使用的本地的缓存展示资源。
Etag标记
基于Etag标记是否一直做判断页面是否发生过变化,比如基于Nginx的Etag on来实现
过期时间 expires
以上两种都需要发送请求,即不管资源是否过期都要发送请求进行协商,这样会消耗不必要的时间,因此有了缓存的过期时间
Expire 是 HttpHeader 中代表资源的过期时间,由服务器端设置。如果带有 Expire ,则在 Expire 过期前不会发生 Http 请求,直接从缓存中读取。用户强制 F5 例外
第一次请求资源时,响应报文带有资源的过期时间,默认为30天,当前此方式使用的比较多,但是无法保证客户的时间都是准确并且一致的,因此会加入一个最大生存周期,使用用户本地的时间计算缓存数据是否超过多少天,假如过期时间Expires:为2031年,但是缓存的最大生存周期Cache-Control: max-age=315360000,计算为天等于3650天即10年
混合使用和缓存刷新
通常 Last-Modified,Etag,Expire 是一起混合使用的
- 特别是 Last-Modified 和 Expire 经常一起使用,因为 Expire 可以让浏览器完全不发起 Http 请求,而当浏览器强制 F5 的时候又有 Last-Modified ,这样就很好的达到了浏览器段缓存的效果。
- Etag 和 Expire 一起使用时,先判断 Expire ,如果已经过期,再发起 Http 请求,如果 Etag 变化了,则返回 200 响应。如果 Etag 没有变化,则返回 304 响应。
- Last-Modified,Etag,Expires 三个同时使用时。先判断 Expire ,然后发送 Http 请求,服务器先判断 last-modified ,再判断 Etag ,必须都没有过期,才能返回 304 响应。
缓存刷新
- 第一次访问,获取最新数据,返回 200响应码
- 鼠标点击二次访问 (Cache),输入地址后回车,浏览器对所有没有过期的内容直接使用本地缓存。
- F5或点刷新按钮, 会向服务器发送请求缓存协商信息,last-modified和etag会有影响,但expires本地过期时间不受影响,无变化返回304
- 按shift+F5强制刷新,所有缓存不再使用,直接连接服务器,获取最新数据,返回200响应码
cookie 和 session
Cookie是访问某些网站以后在本地存储的一些网站相关的信息,下次再访问的时候减少一些步骤,比如加密后的账户名密码等信息
Cookies是服务器在客户端浏览器上存储的小段文本并随每一个请求发送至同一个服务器,是一种实现客户端保持状态的方案。
session称为会话信息,位于web服务器上,主要负责访问者与网站之间的交互,当浏览器请求http地址时,可以基于之前的session实现会话保持、session共享等。
CDN 缓存
什么是CDN
内容分发网络(Content Delivery Network,CDN)是建立并覆盖在承载网上,由不同区域的服务器组成的分布式网络。将源站资源缓存到全国各地的边缘服务器,利用全球调度系统使用户能够就近获取,有效降低访问延迟,降低源站压力,提升服务可用性。
常见的CDN服务商
- 百度CDN:https://cloud.baidu.com/product/cdn.html
- 阿里CDN:https://www.aliyun.com/product/cdn?spm=5176.8269123.416540.50.728y8n
- 腾讯CDN:https://www.qcloud.com/product/cdn
- 腾讯云CDN收费介绍:https://cloud.tencent.com/document/product/228/2949
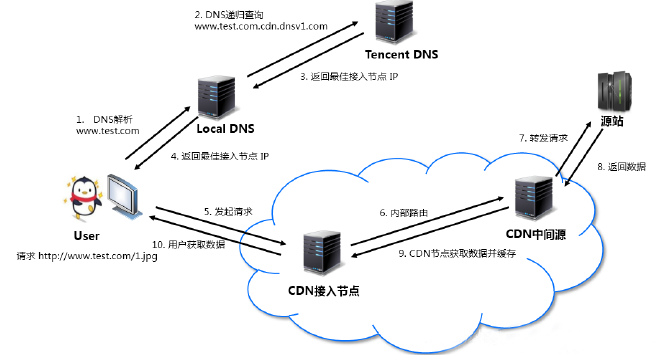
用户请求CDN流程
假设您的业务源站域名为www.test.com,域名接入 CDN 开始使用加速服务后,当您的用户发起HTTP 请求时,实际的处理流程如下图所示:
详细说明如下:
- 用户向www.test.com下的某图片资源(如:1.jpg)发起请求,会先向 Local DNS 发起域名解析请求。
- 当 Local DNS 解析www.test.com时,会发现已经配置了 CNAMEwww.test.com.cdn.dnsv1.com,解析请求会发送至 Tencent DNS(GSLB),GSLB 为腾讯云自主研发的调度体系,会为请求分配最佳节点 IP。
- Local DNS 获取 Tencent DNS 返回的解析 IP。
- 用户获取解析 IP。
- 用户向获取的 IP 发起对资源 1.jpg 的访问请求。
- 若该 IP 对应的节点缓存有 1.jpg,则会将数据直接返回给用户(10),此时请求结束。若该节点未缓存 1.jpg,则节点会向业务源站发起对 1.jpg 的请求(6、7、8),获取资源后,结合用户自定义配置的缓存策略,将资源缓存至节点(9),并返回给用户(10),此时请求结束。
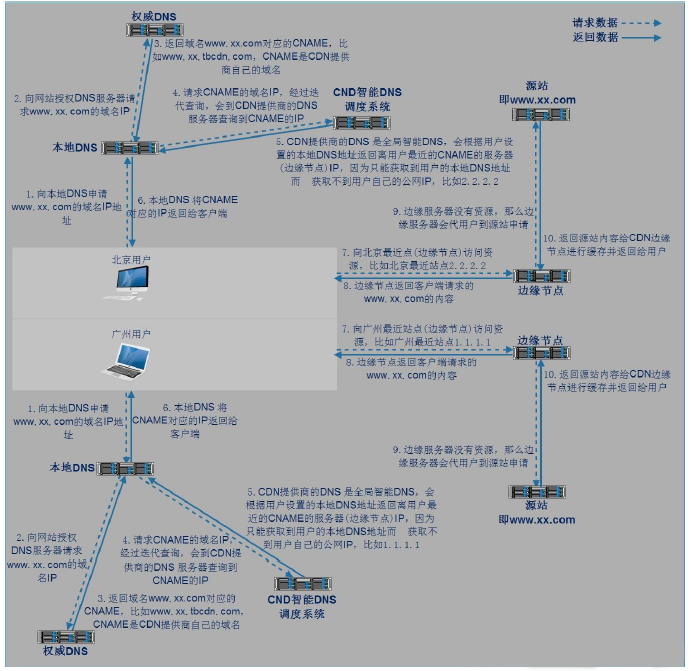
利用 302 实现转发请求重定向至最优服务器集群
因为中国网络较为复杂,依赖DNS就近解析的调度,仍然会存在部分请求调度失效、调度生效慢等问题。
比如:腾讯云利用在全国部署的302重定向服务器集群,能够为每一个请求实时决策最优的服务器资源,精准解决小运营商的调度问题,提升用户访问质量, 能最快地把用户引导到最优的服务器节点上,避开性能差或者异常的节点。
CDN 分层缓存
提前对静态内容进行预缓存,避免大量的请求回源,导致主站网络带宽被打满而导致数据无法更新,另外CDN可以将数据根据访问的热度不同而进行不同级别的缓存,例如:访问量最高的资源访问CDN 边缘节点的内存,其次的放在SSD或者SATA,再其次的放在云存储,这样兼顾了速度与成本。
比如: 腾讯云CDN节点,根据用户的数据冷热不同,动态的进行识别,按照cache层次进行数据的存储,在访问频率到40%-90%的数据,首先放在OC边缘节点内存cache中,提供8G-64G的数据空间存储;在访问频率到30%-50%的数据,放在OC节点SSD/SATA硬盘cache中,提供1T-15T的数据空间存猪,其他的比较冷的数据,放在云存储中,采用回源拉取的方式进行处理。这样在成本和效率中计算出最优平衡点,为客户提供服务。
CDN主要优势
CDN 有效地解决了目前互联网业务中网络层面的以下问题:
- 用户与业务服务器地域间物理距离较远,需要进行多次网络转发,传输延时较高且不稳定。
- 用户使用运营商与业务服务器所在运营商不同,请求需要运营商之间进行互联转发。
- 业务服务器网络带宽、处理能力有限,当接收到海量用户请求时,会导致响应速度降低、可用性降低。
- 利用CDN防止和抵御DDos等攻击,实现安全保护
应用层缓存
Nginx、PHP等web服务可以设置应用缓存以加速响应用户请求,另外有些解释性语言,比如:PHP/Python/Java不能直接运行,需要先编译成字节码,但字节码需要解释器解释为机器码之后才能执行,因此字节码也是一种缓存,有时候还会出现程序代码上线后字节码没有更新的现象。所以一般上线新版前,需要先将应用缓存清理,再上线新版
另外可以利用动态页面静态化技术,加速访问,比如:将访问数据库的数据的动态页面,提前用程序生成静态页面文件html.电商网站的商品介绍,评论信息非实时数据等皆可利用此技术实现
数据层缓存
分布式缓存服务
- Redis
- Memcached
数据库
- MySQL 查询缓存
- innodb缓存、MyISAM缓存
硬件缓存
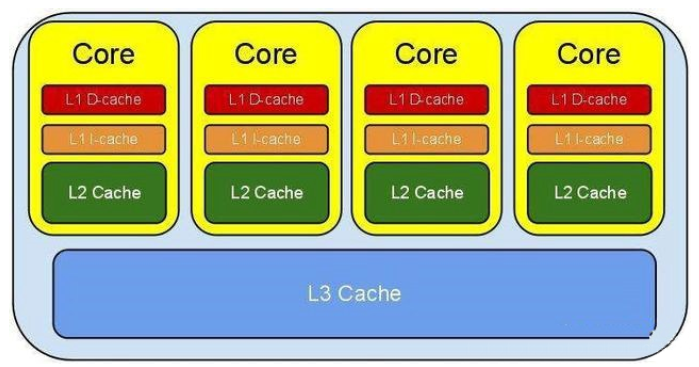
CPU缓存
CPU缓存(L1的数据缓存和L1的指令缓存)、二级缓存、三级缓存
磁盘相关缓存
- 磁盘缓存:Disk Cache
- 磁盘阵列缓存:Raid Cache,可使用电池防止断电丢失数据
redis 基础
redis 简介
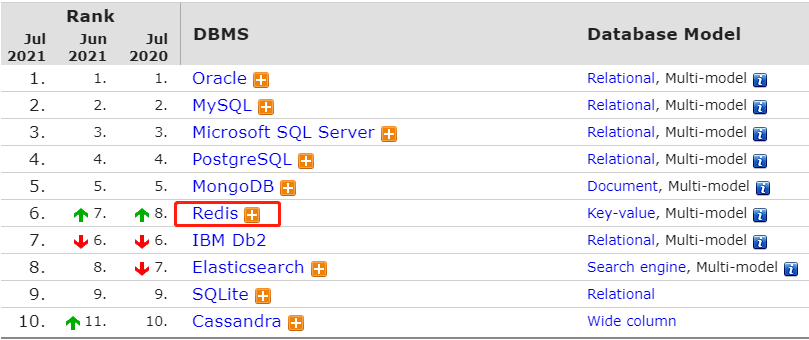
短短几年,Redis就有了很大的用户群体,目前国内外使用的公司众多,比如:阿里,百度,新浪微博,知乎网,GitHub,Twitter 等
Redis是一个开源的、遵循BSD协议的、基于内存的而且目前比较流行的键值数据库(key-value database),是一个非关系型数据库,redis 提供将内存通过网络远程共享的一种服务,提供类似功能的还有memcached,但相比memcached,redis还提供了易扩展、高性能、具备数据持久性等功能。
Redis 在高并发、低延迟环境要求比较高的环境使用量非常广泛,目前redis在DB-Engine月排行榜https://db-engines.com/en/ranking 中一直比较靠前,而且一直是键值型存储类的首位
官网地址:https://redis.io/
Redis 特性
- 速度快: 10W QPS,基于内存,C语言实现
- 单线程
- 持久化
- 支持多种数据结构
- 支持多种编程语言
- 功能丰富: 支持Lua脚本,发布订阅,事务,pipeline等功能
- 简单: 代码短小精悍(单机核心代码只有23000行左右),单线程开发容易,不依赖外部库,使用简单
- 主从复制
- 支持高可用和分布式
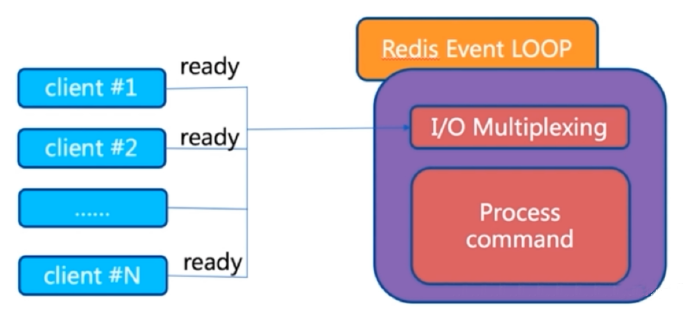
单线程
Redis 6.0版本前一直是单线程方式处理用户的请求

单线程为何如此快?
- 纯内存
- 非阻塞
- 避免线程切换和竞态消耗
注意事项:
- 一次只运行一条命令
- 拒绝长(慢)命令:keys, flushall, flushdb, slow lua script, mutil/exec, operate big value(collection)
- 其实不是单线程: 早期版本是单进程单线程,3版本后实际还有其它的线程, fysnc file descriptor,close file descriptor
redis 对比 memcached
- 支持数据的持久化:可以将内存中的数据保持在磁盘中,重启redis服务或者服务器之后可以从备份文件中恢复数据到内存继续使用
- 支持更多的数据类型:支持string(字符串)、hash(哈希数据)、list(列表)、set(集合)、zset(有序集合)
- 支持数据的备份:可以实现类似于数据的master-slave模式的数据备份,另外也支持使用快照+AOF
- 支持更大的value数据:memcache单个key value最大只支持1MB,而redis最大支持512MB(生产不建议超过2M,性能受影响)
- 在Redis6版本前,Redis 是单线程,而memcached是多线程,所以单机情况下没有memcached 并发高,性能更好,但redis 支持分布式集群以实现更高的并发,单Redis实例可以实现数万并发
- 支持集群横向扩展:基于redis cluster的横向扩展,可以实现分布式集群,大幅提升性能和数据安全性
- 都是基于 C 语言开发
redis 典型应用场景
- Session 共享:常见于web集群中的Tomcat或者PHP中多web服务器session共享
- 缓存:数据查询、电商网站商品信息、新闻内容
- 计数器:访问排行榜、商品浏览数等和次数相关的数值统计场景
- 微博/微信社交场合:共同好友,粉丝数,关注,点赞评论等
- 消息队列:ELK的日志缓存、部分业务的订阅发布系统
- 地理位置: 基于GEO(地理信息定位),实现摇一摇,附近的人,外卖等功能
数据更新操作流程:

数据读操作流程:

Redis 安装及连接
官方下载地址:http://download.redis.io/releases/
yum安装redis
在centos系统上需要安装epel源
查看yum仓库redis版本
[root@localhost ~]# yum -y install epel-release
[root@localhost ~]# yum info redis
yum安装 redis
[root@localhost ~]# yum -y install redis
[root@localhost ~]# systemctl enable --now redis
[root@localhost ~]# pstree -p |grep redis
[root@localhost ~]# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> info
编译安装 redis
下载当前最新release版本 redis 源码包
网站:http://download.redis.io/releases/
编译安装
- 获取软件安装包,安装编译环境
[root@localhost ~]# yum -y install make gcc tcl
[root@localhost ~]# wget http://download.redis.io/releases/redis-5.0.9.tar.gz
[root@localhost ~]# tar xf redis-5.0.9.tar.gz
- 编译安装
[root@localhost ~]# cd redis-5.0.9/
[root@localhost redis-5.0.9]# cd src/
[root@localhost src]# make
[root@localhost src]# make PREFIX=/apps/redis install
- 配置变量
[root@localhost src]# echo "PATH=/apps/redis/bin:$PATH" > /etc/profile.d/redis.sh
[root@localhost src]# . /etc/profile.d/redis.sh
- 目录结构
[root@localhost src]# tree /apps/redis/
/apps/redis/
└── bin
├── redis-benchmark
├── redis-check-aof
├── redis-check-rdb
├── redis-cli
├── redis-sentinel -> redis-server
└── redis-server
1 directory, 6 files
redis-benchmark: 这是 Redis 的性能测试工具,用于测试 Redis 服务器的性能。
redis-check-aof: 这个工具用于检查和修复 Redis 的 Append-Only File (AOF)。AOF 是 Redis 持久化的一种方式,用于记录所有对 Redis 数据库的写入操作。
redis-check-rdb: 这个工具用于检查和修复 Redis 的 RDB 文件。RDB 是 Redis 另一种持久化方式,它会定期将数据库中的数据保存到磁盘上。
redis-cli: 这是 Redis 的命令行客户端工具,可用于连接 Redis 服务器并执行各种操作。
redis-sentinel: 这实际上是一个指向 redis-server 的符号链接。在 Redis 的高可用架构中,Sentinel 是用于监控 Redis 主从复制拓扑并在出现故障时进行自动failover的组件。
redis-server: 这是 Redis 服务器的主程序文件,用于启动和运行 Redis 服务器。
准备相关目录和文件
[root@localhost ~]# mkdir /apps/redis/{etc,log,data,run}
[root@localhost ~]# cp redis-5.0.9/redis.conf /apps/redis/etc/
前台启动 redis
redis-server 是redis 服务器程序
[root@localhost src]# redis-server --help
Usage: ./redis-server [/path/to/redis.conf] [options]
./redis-server - (read config from stdin)
./redis-server -v or --version
./redis-server -h or --help
./redis-server --test-memory <megabytes>
Examples:
./redis-server (run the server with default conf)
./redis-server /etc/redis/6379.conf
./redis-server --port 7777
./redis-server --port 7777 --replicaof 127.0.0.1 8888
./redis-server /etc/myredis.conf --loglevel verbose
Sentinel mode:
./redis-server /etc/sentinel.conf --sentinel
前台启动 redis
[root@localhost src]# redis-server /apps/redis/etc/redis.conf
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.9 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 11791
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
[root@localhost ~]# ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.1:6379 *:*
启动多实例
- 刚刚启动的案例是6379端口,我们可以在6380端口上开启第二个redis服务
- 为6380准备相关目录和文件
[root@localhost ~]# mkdir /apps/redis/6380
[root@localhost ~]# cp -ar /apps/redis/* /apps/redis/6380/
[root@localhost ~]# tree -d /apps/redis/6380
/apps/redis/6380
├── 6380
├── bin
├── data
├── etc
├── log
└── run
6 directories
[root@localhost ~]# vim /apps/redis/6380/etc/redis.conf
port 6380
- 前端启动6380
[root@localhost ~]# redis-server --port 6380
[root@localhost ~]# ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:6379 *:*
LISTEN 0 128 *:6380 *:*
LISTEN 0 128 :::6379 :::*
LISTEN 0 128 :::6380 :::*
[root@localhost ~]# redis-cli -p 6380
127.0.0.1:6380> exit
[root@localhost ~]# redis-cli -p 6379
127.0.0.1:6379> exit
解决启动时的三个警告提示
- tcp-backlog
- backlog参数控制的是三次握手的时候server端收到client.ack确认号之后的队列值,即全连接队列
[root@localhost ~]# echo "net.core.somaxconn = 1024" >> /etc/sysctl.conf
[root@localhost ~]# sysctl -p
net.core.somaxconn = 1024
- vm.overcommit_memory
- 查看警告信息有提示,建议将其值改为1
- 0 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
- 1 表示内核允许分配所有的物理内存,而不管当前的内存状态如何
- 2 表示内核允许分配超过所有物理内存和交换空间总和的内存
[root@localhost ~]# echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
[root@localhost ~]# sysctl -p
net.core.somaxconn = 1024
vm.overcommit_memory = 1
- transparent huge pages
- 警告:您在内核中启用了透明大页面(THP,不同于一般内存页的4k为2M)支持。 这将在Redis中造成延迟和内存使用问题。 要解决此问题,请以root 用户身份运行命令
echo never> /sys/kernel/mm/transparent_hugepage/enabled,并将其添加到您的/etc/rc.local中,以便在重启后保留设置。禁用THP后,必须重新启动Redis。
- 警告:您在内核中启用了透明大页面(THP,不同于一般内存页的4k为2M)支持。 这将在Redis中造成延迟和内存使用问题。 要解决此问题,请以root 用户身份运行命令
[root@localhost ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@localhost ~]# echo "echo never > /sys/kernel/mm/transparent_hugepage/enabled" >> /etc/rc.d/rc.local
[root@localhost ~]# chmod +x /etc/rc.d/rc.local
- 再次启动redis可以看到警告消除,建议在其它redis服务器上做以上配置
创建 redis 用户
[root@localhost ~]# useradd -r -s /sbin/nologin redis
[root@localhost ~]# chown -R redis.redis /apps/redis/
编辑 redis 服务启动文件
- 复制其它主机yum安装生成的redis.service文件,进行修改
[root@localhost ~]# vim /lib/systemd/system/redis.service
[Unit]
Description=Redis persistent key-value database
After=network.target
[Service]
ExecStart=/apps/redis/bin/redis-server /apps/redis/etc/redis.conf --supervised systemd
ExecStop=/bin/kill -s QUIT $MAINPID
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
验证 redis 启动
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl enable --now redis
[root@localhost ~]# ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 511 127.0.0.1:6379 *:*
使用客户端连接 redis
- 格式
redis-cli -h IP/HOSTNAME -p PORT -a PASSWORD
- 连接示例
[root@localhost ~]# redis-cli
127.0.0.1:6379> info
127.0.0.1:6379> exit
创建命令软链接
[root@localhost ~]# ln -s /apps/redis/bin/ /usr/bin/
编译安装后的命令
[root@localhost ~]# ll /apps/redis/bin/
总用量 32772
-rwxr-xr-x. 1 redis redis 4367128 7月 3 21:19 redis-benchmark
-rwxr-xr-x. 1 redis redis 8125424 7月 3 21:19 redis-check-aof
-rwxr-xr-x. 1 redis redis 8125424 7月 3 21:19 redis-check-rdb
-rwxr-xr-x. 1 redis redis 4808096 7月 3 21:19 redis-cli
lrwxrwxrwx. 1 redis redis 12 7月 3 21:19 redis-sentinel -> redis-server
-rwxr-xr-x. 1 redis redis 8125424 7月 3 21:19 redis-server
工具作用
| 工具 | 作用 | | :----------------------------- | :------------------- | | redis-benchmark | redis 性能测试工具 | | redis-check-aof | AOF文件检查工具 | | redis-check-rdb | RDB文件检查工具 | | redis-cli | 客户端工具 | | redis-sentinel -> redis-server | 哨兵,软链接到server | | redis-server | redis 服务启动命令 |
一键编译安装Redis脚本
#!/bin/bash
. /etc/init.d/functions
VERSION=redis-5.0.9
DIR1=/apps/redis
PASSWORD=centos
install() {
yum -y install make wget gcc tcl &> /dev/null || { action "安装所需包失败,请检测包或网络配置" false;exit;}
wget http://download.redis.io/releases/${VERSION}.tar.gz &> /dev/null || { action "Redis 源码下载失败" false; exit; }
tar xf $VERSION.tar.gz
cd $VERSION/
make -j 2 &> /dev/null && make PREFIX=${DIR1} install &> /dev/null && action "Redis 编译安装成功" || { action "Redis 编译安装失败" false;exit; }
ln -s ${DIR1}/bin/* /usr/bin/
mkdir -p ${DIR1}/{etc,data,log,run}
cd
cp $VERSION/redis.conf $DIR1/etc
sed -i -e "s/bind 127.0.0.1/bind 0.0.0.0/" -e "/# requirepass/a requirepass ${PASSWORD}" -e "/^dir .*/c dir ${DIR1}/data/" -e "/logfile .*/c logfile ${DIR1}/log/redis_6379.log" -e "/^pidfile .*/c pidfile ${DIR1}/run/redis_6379.pid" ${DIR1}/etc/redis.conf
if id redis &> /dev/null;then
action "redis 用户已经存在" false
else
useradd -r -s /sbin/nologin redis
action "redis 用户创建成功"
fi
chown -R redis.redis ${DIR1}
cat >> /etc/sysctl.conf <<EOF
net.core.somaxconn = 1024
vm.overcommit_memory = 1
EOF
sysctl -p
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo "echo never > /sys/kernel/mm/transparent_hugepage/enabled" >> /etc/rc.d/rc.local
chmod +x /etc/rc.d/rc.local
/etc/rc.d/rc.local
cat > /lib/systemd/system/redis.service <<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
[Service]
ExecStart=${DIR1}/bin/redis-server ${DIR1}/etc/redis.conf --supervised systemd
ExecStop=/bin/kill -s QUIT \$MAINPID
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now redis &> /dev/null && action "redis 服务启动成功" || { action "redis 服务启动失败" false;exit; }
}
install
连接到 Redis
主要分为客户端连接和程序的连接
客户端连接 redis
- 本机无密码连接
[root@localhost ~]# redis-cli
127.0.0.1:6379>
- 跨主机无密码连接
[root@localhost ~]# redis-cli -h 192.168.88.140 -p 6379
192.168.175.149:6379>
- 跨主机密码连接
[root@localhost ~]# vim /apps/redis/etc/redis.conf
requirepass centos
[root@localhost ~]# systemctl restart redis
[root@localhost ~]# redis-cli -h 192.168.88.140 -p 6379 -a centos --no-auth-warning
192.168.88.140:6379>
-a centos: 使用密码 centos 进行身份验证。
--no-auth-warning: 不显示身份验证警告消息。
程序连接 Redis
- redis 支持多种开发语言访问https://redis.io/clients
shell 连接方式
[root@localhost ~]# vim redis_test.sh
#!/bin/bash
NUM=`seq 1 10000`
PASS=centos
for i in ${NUM};do
redis-cli -h 127.0.0.1 -a "$PASS" --no-auth-warning set key-${i} value-${i}
echo "key-${i} value-${i} 写入完成"
done
echo "一万个key写入到Redis完成"
[root@localhost ~]# vim /apps/redis/etc/redis.conf#这边临时关闭RDB,不然会报错
save ""
#save 900 1
#save 300 10
#save 60 10000
[root@localhost ~]# systemctl restart redis
[root@localhost ~]# time bash redis_test.sh
一万个key写入到Redis完成
real 0m22.874s
user 0m3.885s
sys 0m17.958s
[root@localhost ~]# redis-cli
127.0.0.1:6379> auth centos
OK
127.0.0.1:6379> keys *
127.0.0.1:6379> get key-996
"value-996"
127.0.0.1:6379> flushdb # 清空当前库的数据
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> flushall # 清空所有的数据
OK
python 连接方式
- python 多种开发库,可以支持连接redis
- 安装python运行环境
[root@localhost ~]# yum -y install python3 python3-redis
- 编写python程序
[root@localhost ~]# vim redis_test.py
#!/bin/env python3
import redis
#import time
pool = redis.ConnectionPool(host="127.0.0.1",port=6379,password="centos")
r = redis.Redis(connection_pool=pool)
for i in range(100):
r.set("k%d" % i,"v%d" % i)
# time.sleep(1)
data=r.get("k%d" % i)
print(data)
[root@localhost ~]# python3 redis_test.py
- 验证数据是否正确插入
[root@localhost ~]# redis-cli -a centos --no-auth-warning
127.0.0.1:6379> get k88
"v88"
redis 的多实例
- 测试环境中经常使用多实例,需要指定不同实例的相应的端口,配置文件,日志文件等相关配置
- 以编译安装为例实现 redis 多实例
- 修改配置文件和启动服务
[root@localhost ~]# cd /apps/redis/
[root@localhost redis]# mv etc/redis.conf etc/redis_6379.conf
[root@localhost redis]# vim etc/redis_6379.conf
port 6379
pidfile /apps/redis/run/redis_6379.pid
logfile "/apps/redis/log/redis_6379.log"
dbfilename dumpi_6379.rdb
dir /apps/redis/data
appendfilename "appendonlyi_6379.aof"
[root@localhost redis]# mv /lib/systemd/system/redis.service /lib/systemd/system/redis_6379.service
[root@localhost redis]# vim /lib/systemd/system/redis_6379.service
ExecStart=/apps/redis/bin/redis-server /apps/redis/etc/redis_6379.conf --supervised systemd
[root@localhost redis]# systemctl restart redis_6379.service
- 按照同样的方式,启动6380和6381实例
cp -a etc/redis_6379.conf etc/redis_6380.conf
sed -i "s/6379/6380/g" etc/redis_6380.conf
cp -a /lib/systemd/system/redis_6379.service /lib/systemd/system/redis_6380.service
sed -i "s/6379/6380/g" /lib/systemd/system/redis_6380.service
systemctl enable --now redis_6380.service
cp -a etc/redis_6379.conf etc/redis_6381.conf
sed -i "s/6379/6381/g" etc/redis_6381.conf
cp -a /lib/systemd/system/redis_6379.service /lib/systemd/system/redis_6381.service
sed -i "s/6379/6381/g" /lib/systemd/system/redis_6381.service
systemctl daemon-reload
systemctl enable --now redis_6381.service
- 验证端口号
[root@localhost redis]# ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 511 *:6379 *:*
LISTEN 0 511 *:6380 *:*
LISTEN 0 511 *:6381 *:*
- 查看文件结构目录
[root@localhost redis]# tree
.
├── bin
│ ├── redis-benchmark
│ ├── redis-check-aof
│ ├── redis-check-rdb
│ ├── redis-cli
│ ├── redis-sentinel -> redis-server
│ └── redis-server
├── data
├── etc
│ ├── redis_6379.conf
│ ├── redis_6380.conf
│ └── redis_6381.conf
├── log
│ ├── redis_6379.log
│ ├── redis_6380.log
│ └── redis_6381.log
└── run
├── redis_6379.pid
├── redis_6380.pid
└── redis_6381.pid
5 directories, 15 files
redis 配置和优化
redis 主要配置项
- redis常用配置参数
bind 0.0.0.0 #监听地址,可以用空格隔开后多个监听IP
protected-mode yes #redis3.2之后加入的新特性,在没有设置bind IP和密码的时候,redis只允许访问127.0.0.1:6379,可以远程连接,但当访问将提示警告信息并拒绝远程访问
port 6379 #监听端口,默认6379/tcp
tcp-backlog 511 #三次握手的时候server端收到client ack确认号之后的队列值,即全连接队列长度
timeout 0 #客户端和Redis服务端的连接超时时间,默认是0,表示永不超时
tcp-keepalive 300 #tcp 会话保持时间300s
daemonize no #默认no,即直接运行redis-server程序时,不作为守护进程运行,而是以前台方式运行,如果想在后台运行需改成yes,当redis作为守护进程运行的时候,它会写一个 pid 到/var/run/redis.pid 文件
supervised no #和OS相关参数,可设置通过upstart和systemd管理Redis守护进程,centos7后都使用systemdpidfile /var/run/redis_6379.pid #pid文件路径,可以修改为/apps/redis/run/redis_6379.pid
loglevel notice #日志级别
logfile "/path/redis.log" #日志路径,示例:logfile"/apps/redis/log/redis_6379.log"
databases 16 #设置数据库数量,默认:0-15,共16个库
always-show-logo yes #在启动redis 时是否显示或在日志中记录记录redis的logo
- 快照配置
save 900 1 #在900秒内有1个key内容发生更改,就执行快照机制
save 300 10 #在300秒内有10个key内容发生更改,就执行快照机制
save 60 10000 #60秒内如果有10000个key以上的变化,就自动快照备份
stop-writes-on-bgsave-error yes #默认为yes时,可能会因空间满等原因快照无法保存出错时,会禁止redis写入操作,生产建议为no #此项只针对配置文件中的自动save有效
rdbcompression yes #持久化到RDB文件时,是否压缩,"yes"为压缩,"no"则反之
rdbchecksum yes #是否对备份文件开启RC64校验,默认是开启
dbfilename dump.rdb #快照文件名
dir ./ #快照文件保存路径,示例:dir "/apps/redis/data"
- 主从复制相关配置
# replicaof <masterip> <masterport> #指定复制的master主机地址和端口,5.0版之前的指令为slaveof
# masterauth <master-password> #指定复制的master主机的密码
replica-serve-stale-data yes #当从库同主库失去连接或者复制正在进行,从机库有两种运行方式:
1、设置为yes(默认设置),从库会继续响应客户端的读请求,此为建议值
2、设置为no,除去特定命令外的任何请求都会返回一个错误"SYNC with master in progress"。
replica-read-only yes #是否设置从库只读,建议值为yes,否则主库同步从库时可能会覆盖数据,造成数据丢失
repl-diskless-sync no #是否使用socket方式复制数据(无盘同步),新slave第一次连接master时需要做数据的全量同步,redis server就要从内存dump出新的RDB文件,然后从master传到slave,有两种方式把RDB文件传输给客户端:
1、基于硬盘(disk-backed):为no时,master创建一个新进程dump生成RDB磁盘文件,RDB完成之后由
父进程(即主进程)将RDB文件发送给slaves,此为默认值
2、基于socket(diskless):master创建一个新进程直接dump RDB至slave的网络socket,不经过主进程和硬盘
#推荐使用基于硬盘(为no),是因为RDB文件创建后,可以同时传输给更多的slave,但是基于socket(为yes), 新slave连接到master之后得逐个同步数据。只有当磁盘I/O较慢且网络较快时,可用diskless(yes),否则一般建议使用磁盘(no)
repl-diskless-sync-delay 5 #diskless时复制的服务器等待的延迟时间,设置0为关闭,在延迟时间内到达的客户端,会一起通过diskless方式同步数据,但是一旦复制开始,master节点不会再接收新slave的复制请求,直到下一次同步开始才再接收新请求。即无法为延迟时间后到达的新副本提供服务,新副本将排队等待下一次RDB传输,因此服务器会等待一段时间才能让更多副本到达。推荐值:30-60
repl-ping-replica-period 10 #slave根据master指定的时间进行周期性的PING master,用于监测master状态,默认10s
repl-timeout 60 #复制连接的超时时间,需要大于repl-ping-slave-period,否则会经常报超时
repl-disable-tcp-nodelay no #是否在slave套接字发送SYNC之后禁用 TCP_NODELAY,如果选择"yes",Redis将合并多个报文为一个大的报文,从而使用更少数量的包向slaves发送数据,但是将使数据传输到slave上有延迟,Linux内核的默认配置会达到40毫秒,如果 "no" ,数据传输到slave的延迟将会减少,但要使用更多的带宽
repl-backlog-size 512mb #复制缓冲区内存大小,当slave断开连接一段时间后,该缓冲区会累积复制副本数据,因此当slave 重新连接时,通常不需要完全重新同步,只需传递在副本中的断开连接后没有同步的部分数据即可。只有在至少有一个slave连接之后才分配此内存空间,建议建立主从时此值要调大一些或在低峰期配置,否则会导致同步到slave失败
repl-backlog-ttl 3600 #多长时间内master没有slave连接,就清空backlog缓冲区
replica-priority 100 #当master不可用,哨兵Sentinel会根据slave的优先级选举一个master,此值最低的slave会当选master,而配置成0,永远不会被选举,一般多个slave都设为一样的值,让其自动选择
#min-replicas-to-write 3 #至少有3个可连接的slave,mater才接受写操作
#min-replicas-max-lag 10 #和上面至少3个slave的ping延迟不能超过10秒,否则master也将停止写操作
requirepass foobared #设置redis连接密码,之后需要AUTH pass,如果有特殊符号,用" "引起来,生产建议设置
rename-command #重命名一些高危命令,示例:rename-command FLUSHALL "" 禁用命令
#示例: rename-command del areyouok
- 客户端配置
maxclients 10000 #Redis最大连接客户端
maxmemory <bytes> #redis使用的最大内存,单位为bytes字节,0为不限制,建议设为物理内存一半,8G内存的计算方式8(G)*1024(MB)1024(KB)*1024(Kbyte),需要注意的是缓冲区是不计算在maxmemory内,生产中如果不设置此项,可能会导致BOOM
appendonly no #是否开启AOF日志记录,默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了,但是redis如果中途宕机,会导致可能有几分钟的数据丢失(取决于dump数据的间隔时间),根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性,Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。默认不启用此功能
appendfilename "appendonly.aof" #文本文件AOF的文件名,存放在dir指令指定的目录中
appendfsync everysec #aof持久化策略的配置
#no表示由操作系统保证数据同步到磁盘,Linux的默认fsync策略是30秒,最多会丢失30s的数据
#always表示每次写入都执行fsync,以保证数据同步到磁盘,安全性高,性能较差
#everysec表示每秒执行一次fsync,可能会导致丢失这1s数据,此为默认值,也生产建议值
#同时在执行bgrewriteaof操作和主进程写aof文件的操作,两者都会操作磁盘,而bgrewriteaof往往会涉及大量磁盘操作,这样就会造成主进程在写aof文件的时候出现阻塞的情形,以下参数实现控制
no-appendfsync-on-rewrite no #在aof rewrite期间,是否对aof新记录的append暂缓使用文件同步策略,主要考虑磁盘IO开支和请求阻塞时间。
#默认为no,表示"不暂缓",新的aof记录仍然会被立即同步到磁盘,是最安全的方式,不会丢失数据,但是要忍受阻塞的问题
#为yes,相当于将appendfsync设置为no,这说明并没有执行磁盘操作,只是写入了缓冲区,因此这样并不会造成阻塞(因为没有竞争磁盘),但是如果这个时候redis挂掉,就会丢失数据。丢失多少数据呢?Linux的默认fsync策略是30秒,最多会丢失30s的数据,但由于yes性能较好而且会避免出现阻塞因此比较推荐
#rewrite 即对aof文件进行整理,将空闲空间回收,从而可以减少恢复数据时间
auto-aof-rewrite-percentage 100 #当Aof log增长超过指定百分比例时,重写AOF文件,设置为0表示不自动重写Aof日志,重写是为了使aof体积保持最小,但是还可以确保保存最完整的数据
auto-aof-rewrite-min-size 64mb #触发aof rewrite的最小文件大小
aof-load-truncated yes #是否加载由于某些原因导致的末尾异常的AOF文件(主进程被kill/断电等),建议yes
aof-use-rdb-preamble no #redis4.0新增RDB-AOF混合持久化格式,在开启了这个功能之后,AOF重写产生的文件将同时包含RDB格式的内容和AOF格式的内容,其中RDB格式的内容用于记录已有的数据,而AOF格式的内容则用于记录最近发生了变化的数据,这样Redis就可以同时兼有RDB持久化和AOF持久化的优点(既能够快速地生成重写文件,也能够在出现问题时,快速地载入数据),默认为no,即不启用此功能
lua-time-limit 5000 #lua脚本的最大执行时间,单位为毫秒
cluster-enabled yes #是否开启集群模式,默认不开启,即单机模式
cluster-config-file nodes-6379.conf #由node节点自动生成的集群配置文件名称
cluster-node-timeout 15000 #集群中node节点连接超时时间,单位ms,超过此时间,会踢出集群
cluster-replica-validity-factor 10 #单位为次,在执行故障转移的时候可能有些节点和master断开一段时间导致数据比较旧,这些节点就不适用于选举为master,超过这个时间的就不会被进行故障转移,不能当选master,计算公式:(node-timeout * replica-validity-factor) + repl-pingreplica-period
cluster-migration-barrier 1 #集群迁移屏障,一个主节点至少拥有1个正常工作的从节点,即如果主节点的slave节点故障后会将多余的从节点分配到当前主节点成为其新的从节点。
cluster-require-full-coverage yes #集群请求槽位全部覆盖,如果一个主库宕机且没有备库就会出现集群槽位不全,那么yes时redis集群槽位验证不全,就不再对外提供服务(对key赋值时,会出现CLUSTERDOWN The cluster is down的示,cluster_state:fail,但ping 仍PONG),而no则可以继续使用,但是会出现查询数据查不到的情况(因为有数据丢失)。生产建议为no
cluster-replica-no-failover no #如果为yes,此选项阻止在主服务器发生故障时尝试对其主服务器进行故障转移。 但是,主服务器仍然可以执行手动强制故障转移,一般为no
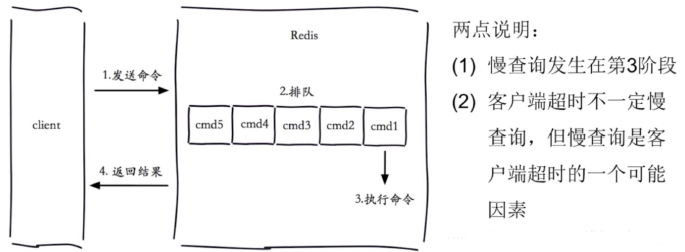
#Slow log 是 Redis 用来记录超过指定执行时间的日志系统,执行时间不包括与客户端交谈,发送回复等I/O操作,而是实际执行命令所需的时间(在该阶段线程被阻塞并且不能同时为其它请求提供服务),由于slow log 保存在内存里面,读写速度非常快,因此可放心地使用,不必担心因为开启 slow log 而影响Redis 的速度
slowlog-log-slower-than 10000 #以微秒为单位的慢日志记录,为负数会禁用慢日志,为0会记录每个命令操作。默认值为10ms,一般一条命令执行都在微秒级,生产建议设为1ms
slowlog-max-len 128 #最多记录多少条慢日志的保存队列长度,达到此长度后,记录新命令会将最旧的命令从命令队列中删除,以此滚动删除,即,先进先出,队列固定长度,默认128,值偏小,生产建议设为1000以上
CONFIG 动态修改配置
- config 命令用于查看当前redis配置、以及不重启redis服务实现动态更改redis配置等
- 注意:不是所有配置都可以动态修改,且此方式无法持久保存
redis 127.0.0.1:6379> CONFIG SET parameter value
时间复杂度:O(1)
CONFIG SET 命令可以动态地调整 Redis 服务器的配置(configuration)而无须重启。
redis 127.0.0.1:6379> CONFIG GET slowlog-max-len
1) "slowlog-max-len"
2) "1024"
redis 127.0.0.1:6379> CONFIG SET slowlog-max-len 10086
OK
redis 127.0.0.1:6379> CONFIG GET slowlog-max-len
1) "slowlog-max-len"
2) "10086"
设置连接密码
#设置连接密码
127.0.0.1:6379> CONFIG SET requirepass centos
OK
#查看连接密码
127.0.0.1:6379> CONFIG GET requirepass
1) "requirepass"
2) "centos"
获取当前配置
#奇数行为键,偶数行为值
127.0.0.1:6379> CONFIG GET *
#查看bind
127.0.0.1:6379> CONFIG GET bind
1) "bind"
2) "0.0.0.0"
#有些设置无法修改
127.0.0.1:6379> CONFIG SET bind 127.0.0.1
(error) ERR Unsupported CONFIG parameter: bind
更改最大内存
127.0.0.1:6379> CONFIG SET maxmemory 8589934592
OK
127.0.0.1:6379> CONFIG GET maxmemory
1) "maxmemory"
2) "8589934592"
慢查询
- 可以通过config set命令动态修改参数,并使配置持久化到配置文件中
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1000
config rewrite
- 获取慢查询日志,将慢查询的时间改为1微秒
127.0.0.1:6379> config set slowlog-log-slower-than 1
OK
127.0.0.1:6379> config set slowlog-max-len 1000
OK
127.0.0.1:6379> SLOWLOG len
# 获取慢查询日志列表当前的长度
(integer) 2
127.0.0.1:6379> SLOWLOG get
1) 1) (integer) 2
2) (integer) 1625544379
3) (integer) 1
4) 1) "SLOWLOG"
2) "len"
5) "127.0.0.1:40294"
6) ""
2) 1) (integer) 1
2) (integer) 1625544372
3) (integer) 4
4) 1) "config"
2) "set"
3) "slowlog-max-len"
4) "1000"
5) "127.0.0.1:40294"
6) ""
3) 1) (integer) 0
2) (integer) 1625544363
3) (integer) 3
4) 1) "config"
2) "set"
3) "slowlog-log-slower-than"
4) "1"
5) "127.0.0.1:40294"
6) ""
- 可以看到每个慢查询日志有4个属性组成,分别是慢查询日志的标识id、发生时间戳、命令耗时、执行命令和参数
- 慢查询日志重置
127.0.0.1:6379> slowlog reset
OK
127.0.0.1:6379> slowlog len
(integer) 0
redis持久化
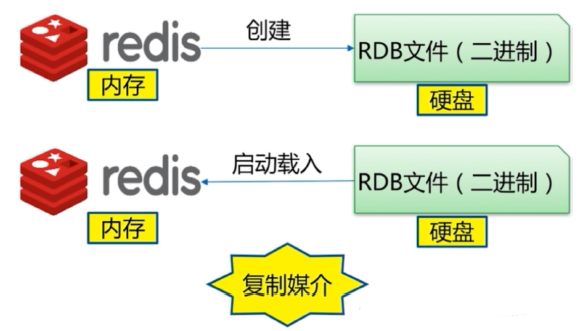
Redis 虽然是一个内存级别的缓存程序,也就是redis 是使用内存进行数据的缓存的,但是其可以将内存的数据按照一定的策略保存到硬盘上,从而实现数据持久保存的目的
目前redis支持两种不同方式的数据持久化保存机制,分别是RDB和AOF

RDB 模式
RDB 模式工作原理
RDB(Redis DataBase):基于时间的快照,其默认只保留当前最新的一次快照,特点是执行速度比较快,缺点是可能会丢失从上次快照到当前时间点之间未做快照的数据
RDB bgsave 实现快照的具体过程

- Redis从master主进程先fork出一个子进程,使用写时复制机制,子进程将内存的数据保存为一个临时文件
- 当数据保存完成之后再将上一次保存的RDB文件替换掉,然后关闭子进程,这样可以保证每一次做RDB快照保存的数据都是完整的
- 因为直接替换RDB文件的时候,可能会出现突然断电等问题,而导致RDB文件还没有保存完整就因为突然关机停止保存,而导致数据丢失的情况.后续可以手动将每次生成的RDB文件进行备份,这样可以最大化保存历史数据
[root@localhost redis]# pstree -p |grep redis-server;ll -h /apps/redis/data/
|-redis-server(6831)-+-{redis-server}(6849)
| |-{redis-server}(6850)
| `-{redis-server}(6851)
|-redis-server(34300)-+-{redis-server}(34301)
| |-{redis-server}(34302)
| `-{redis-server}(34303)
总用量 204K
-rw-r--r--. 1 redis redis 204K 7月 6 12:28 dumpi_6379.rdb
RDB 相关配置
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /var/lib/redis #编译安装,默认RDB文件存放在启动redis的工作目录,建议明确指定存入目录
实现RDB方式
- bgsave:异步后台执行,不影响其它命令的执行
- 自动: 制定规则,自动执行
RDB 模式优点
- RDB快照保存了某个时间点的数据,可以通过脚本执行redis指令bgsave(非阻塞,后台执行)或者save(会阻塞写操作,不推荐)命令自定义时间点备份,可以保留多个备份,当出现问题可以恢复到不同时间点的版本,很适合备份,并且此文件格式也支持有不少第三方工具可以进行后续的数据分析
- 比如: 可以在最近的24小时内,每小时备份一次RDB文件,并且在每个月的每一天,也备份一个ROB文件。这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。
- RDB可以最大化Redis的性能,父进程在保存 RDB文件时唯一要做的就是fork出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘工/0操作。
- RDB在大量数据,比如几个G的数据,恢复的速度比AOF的快
RDB 模式缺点
- 不能实时保存数据,可能会丢失自上一次执行RDB备份到当前的内存数据
- 如果你需要尽量避免在服务器故障时丢失数据,那么RDB不适合你。虽然Redis允许你设置不同的保存点(save point)来控制保存RDB文件的频率,但是,因为RDB文件需要保存整个数据集的状态,所以它并不是一个轻松的操作。因此你可能会至少5分钟才保存一次RDB文件。在这种情况下,一旦发生故障停机,你就可能会丢失好几分钟的数据。
- 当数据量非常大的时候,从父进程fork子进程进行保存至RDB文件时需要一点时间,可能是毫秒或者秒,取决于磁盘IO性能
- 在数据集比较庞大时,fork()可能会非常耗时,造成服务器在一定时间内停止处理客户端﹔如果数据集非常巨大,并且CPU时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒或更久。虽然 AOF重写也需要进行fork(),但无论AOF重写的执行间隔有多长,数据的持久性都不会有任何损失。
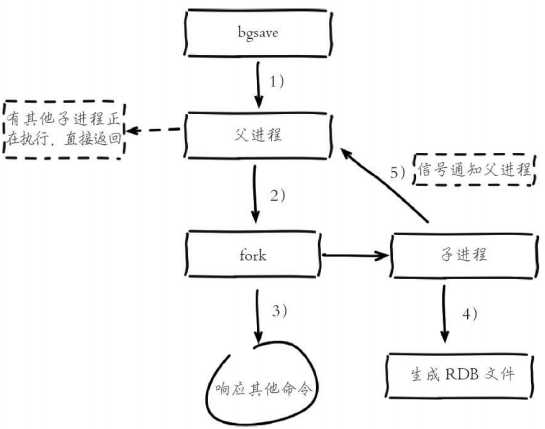
- 执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进 程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
- 父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通 过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒。
- 父进程fork完成后,bgsave命令返回“Background saving started”信息 并不再阻塞父进程,可以继续响应其他命令。
- 子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的 时间,对应info统计的rdb_last_save_time选项。
- 进程发送信号给父进程表示完成,父进程更新统计信息,
AOF 模式
AOF 模式工作原理

- AOF:AppendOnylFile,按照操作顺序依次将操作追加到指定的日志文件末尾
- AOF 和 RDB 一样使用了写时复制机制,AOF默认为每秒钟 fsync一次,即将执行的命令保存到AOF文件当中,这样即使redis服务器发生故障的话最多只丢失1秒钟之内的数据,也可以设置不同的fsync策略always,即设置每次执行命令的时候执行fsync,fsync会在后台执行线程,所以主线程可以继续处理用户的正常请求而不受到写入AOF文件的I/O影响
- 同时启用RDB和AOF,进行恢复时,默认AOF文件优先级高于RDB文件,即会使用AOF文件进行恢复
- 注意: AOF 模式默认是关闭的,第一次开启AOF后,并重启服务生效后,会因为AOF的优先级高于RDB,而AOF默认没有文件存在,从而导致所有数据丢失
AOF rewrite 重写
将一些重复的,可以合并的,过期的数据重新写入一个新的AOF文件,从而节约AOF备份占用的硬盘空间,也能加速恢复过程
可以手动执行bgrewriteaof 触发AOF,或定义自动rewrite 策略
AOF rewrite 过程
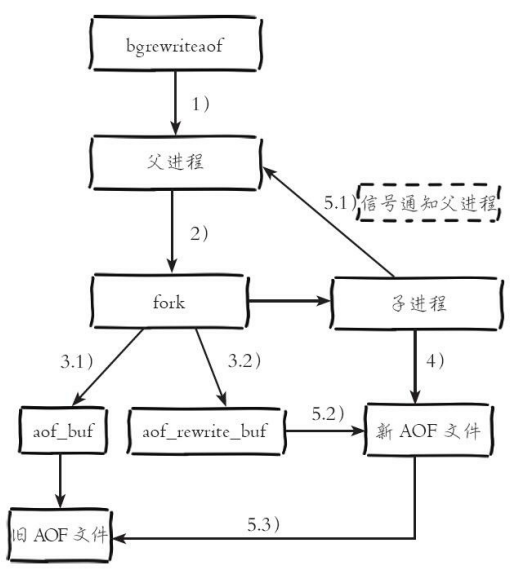
1.执行AOF重写请求。
2.父进程执行fork创建子进程,开销等同于bgsave过程。
3.1主进程fork操作完成后,继续响应其他命令。所有修改命令依然写 入AOF缓冲区并根据appendfsync策略同步到硬盘,保证原有AOF机制正确 性。
3.2由于fork操作运用写时复制技术,子进程只能共享fork操作时的内 存数据。由于父进程依然响应命令,Redis使用“AOF重写缓冲区”保存这部 分新数据,防止新AOF文件生成期间丢失这部分数据。
4.子进程根据内存快照,按照命令合并规则写入到新的AOF文件。每次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为 32MB,防止单次刷盘数据过多造成硬盘阻塞。
5.1新AOF文件写入完成后,子进程发送信号给父进程,父进程更新 统计信息,具体见info persistence下的aof_*相关统计。
5.2父进程把AOF重写缓冲区的数据写入到新的AOF文件。
5.3使用新AOF文件替换老文件,完成AOF重写。
# 用AOF功能的正确方式
[root@localhost data]# ll
总用量 204
-rw-r--r--. 1 redis redis 207886 7月 6 12:28 dumpi_6379.rdb
[root@localhost data]# redis-cli
127.0.0.1:6379> config get appendonly
1) "appendonly"
2) "no"
127.0.0.1:6379> config set appendonly yes
127.0.0.1:6379> CONFIG REWRITE
OK
[root@localhost data]# ll
总用量 408
-rw-r--r--. 1 redis redis 207886 7月 6 13:45 appendonlyi_6379.aof
-rw-r--r--. 1 redis redis 207886 7月 6 12:28 dumpi_6379.rdb
AOF相关配置
appendonly yes
appendfilename "appendonly-${port}.aof"
appendfsync everysec
dir /path
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
AOF 模式优点
- 数据安全性相对较高,根据所使用的fsync策略(fsync是同步内存中redis所有已经修改的文件到存储设备),默认是appendfsync everysec,即每秒执行一次 fsync,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync会在后台线程执行,所以主线程可以继续努力地处理命令请求)
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中不需要seek, 即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,可以通过 redis-check-aof 工具来解决数据一致性的问题
- Redis可以在 AOF文件体积变得过大时,自动地在后台对AOF进行重写,重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新 AOF文件的过程中,append模式不断的将修改数据追加到现有的 AOF文件里面,即使重写过程中发生停机,现有的 AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,也可以通过该文件完成数据的重建。
- AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此 AOF文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出(export)AOF文件也非常简单:举个例子,如果你不小心执行了FLUSHALL.命令,但只要AOF文件未被重写,那么只要停止服务器,移除 AOF文件末尾的FLUSHAL命令,并重启Redis ,就可以将数据集恢复到FLUSHALL执行之前的状态。
AOF 模式缺点
- 即使有些操作是重复的也会全部记录,AOF 的文件大小要大于 RDB 格式的文件
- AOF 在恢复大数据集时的速度比 RDB 的恢复速度要慢
- 根据fsync策略不同,AOF速度可能会慢于RDB
- bug 出现的可能性更多
RDB和AOF 的选择
如果主要充当缓存功能,或者可以承受数分钟数据的丢失, 通常生产环境一般只需启用RDB即可,此也是默认值
如果数据需要持久保存,一点不能丢失,可以选择同时开启RDB和AOF,一般不建议只开启AOF
Redis 常用命令
参考链接:http://redisdoc.com/
INFO
- 显示当前节点redis运行状态信息
127.0.0.1:6379> info
SELECT
- 切换数据库,相当于在MySQL的 USE DBNAME 指令
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> select 15
OK
127.0.0.1:6379[15]> select 16
(error) ERR DB index is out of range
- 注意: 在 redis cluster 模式下不支持多个数据库,会出现下面错误
127.0.0.1:6379> info cluster
# Cluster
cluster_enabled:1
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> select 1
(error) ERR SELECT is not allowed in cluster mode
KEYS
- 查看当前库下的所有key,此命令慎用!
| 命令 | 时间复杂度 |
|---|---|
| keys | O(n) |
| dbsize | O(1) |
| del | O(1) |
| exists | O(1) |
| expire | O(1) |
| type | O(1) |
127.0.0.1:6379[1]> SELECT 0
OK
127.0.0.1:6379> KEYS * #匹配数据库内所有key
1) "port1"
2) "name"
3) "port2"
4) "port"
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> KEYS *
(empty list or set)
127.0.0.1:6379[1]>
127.0.0.1:6379> SELECT 1
OK
#一次设置4个key
127.0.0.1:6379[1]> MSET one 1 two 2 three 3 four 4
OK
127.0.0.1:6379[1]> KEYS *
1) "two"
2) "one"
3) "four"
BGSAVE
- 手动在后台执行RDB持久化操作
#交互式执行
127.0.0.1:6379[1]> BGSAVE
Background saving started
[root@centos8 ~]#ll /apps/redis/data/
total 664
-rw-r--r-- 1 redis redis 204 Oct 22 21:30 dump_6379.rdb
#非交互式执行
[root@centos8 ~]#redis-cli -a centos --no-auth-warning bgsave
Background saving started
[root@centos8 ~]#ll /apps/redis/data/
total 664
-rw-r--r-- 1 redis redis 204 Oct 22 21:32 dump_6379.rdb
DBSIZE
- 返回当前库下的所有key 数量
127.0.0.1:6379> DBSIZE
(integer) 8
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> DBSIZE
(integer) 4
127.0.0.1:6379[1]> SELECT 2
OK
127.0.0.1:6379[2]> DBSIZE
(integer) 0
FLUSHDB
- 强制清空当前库中的所有key,此命令慎用!
127.0.0.1:6379[2]> SELECT 1
OK
127.0.0.1:6379[1]> DBSIZE
(integer) 4
127.0.0.1:6379[1]> FLUSHDB
OK
127.0.0.1:6379[1]> DBSIZE
(integer) 0
FLUSHALL
- 强制清空当前redis服务器所有数据库中的所有key,即删除所有数据,此命令慎用!
127.0.0.1:6379> FLUSHALL
OK
#生产建议修改配置 /etc/redis.conf,禁用或改为别名
rename-command FLUSHALL ""
SHUTDOWN
- SHUTDOWN 命令执行以下操作:
- 停止所有客户端
- 如果有至少一个保存点在等待,执行 SAVE 命令
- 如果 AOF 选项被打开,更新 AOF 文件
- 关闭 redis 服务器(server)
- 如果持久化被打开的话, SHUTDOWN 命令会保证服务器正常关闭而不丢失任何数据。
- 另一方面,假如只是单纯地执行 SAVE 命令,然后再执行 QUIT 命令,则没有这一保证因为在执行SAVE 之后、执行 QUIT 之前的这段时间中间,其他客户端可能正在和服务器进行通讯,这时如果执行QUIT 就会造成数据丢失。
redis 数据类型


字符串 string
字符串是所有编程语言中最常见的和最常用的数据类型,而且也是redis最基本的数据类型之一,而且redis 中所有的 key 的类型都是字符串。常用于保存 Session 信息场景,此数据类型比较常用
- 添加一个key
- set 指令可以创建一个key 并赋值, 使用格式
127.0.0.1:6379> set key1 value1
OK
127.0.0.1:6379> set title ceo ex 5 #设置自动过期时间为5秒
OK
127.0.0.1:6379> get title
"ceo"
127.0.0.1:6379> get title
(nil)
127.0.0.1:6379> set NAME eagle #大小写敏感
OK
127.0.0.1:6379> get name
(nil)
#key不存在才设置,相当于add
127.0.0.1:6379> set name eagle
OK
127.0.0.1:6379> get name
"eagle"
127.0.0.1:6379> set name xwz nx
(nil)
127.0.0.1:6379> get name
"eagle"
#key存在才设置,相当于update
127.0.0.1:6379> get name
"eagle"
127.0.0.1:6379> set name xwz xx
OK
127.0.0.1:6379> get name
"xwz"
127.0.0.1:6379> get age
(nil)
127.0.0.1:6379> set age 18 xx
(nil)
127.0.0.1:6379> get age
(nil)
- 获取一个key的内容
127.0.0.1:6379> get name
"xwz"
127.0.0.1:6379> get name age
(error) ERR wrong number of arguments for 'get' command
- 删除一个和多个key
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> del age NAME
(integer) 2
- 批量设置多个key
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
- 批量获取多个key
127.0.0.1:6379> mget k1 k2
1) "v1"
2) "v2"
127.0.0.1:6379> keys *
1) "k2"
2) "k3"
3) "k1"
127.0.0.1:6379> keys k*
1) "k2"
2) "k3"
3) "k1"
- 追加数据
127.0.0.1:6379> append k2 " append new value"
(integer) 19
127.0.0.1:6379> get k2
"v2 append new value"
- 设置新值并返回旧值
127.0.0.1:6379> set name eagle
OK
127.0.0.1:6379> getset name xwz
"eagle"
127.0.0.1:6379> get name
"xwz"
- 返回字符串 key 对应值的字节数
127.0.0.1:6379> set name eagle
OK
127.0.0.1:6379> strlen name #返回字节数
(integer) 5
127.0.0.1:6379> append name " xwz"
(integer) 9
127.0.0.1:6379> get name
"eagle xwz"
127.0.0.1:6379> strlen name
(integer) 9
127.0.0.1:6379> set name 好好学习
OK
127.0.0.1:6379> strlen name
(integer) 12
- 判断 key 是否存在
127.0.0.1:6379> set name eagle ex 5
OK
127.0.0.1:6379> exists name
(integer) 1
127.0.0.1:6379> exists name
(integer) 0
- 查看 key 的过期时间
- ttl key #查看key的剩余生存时间,如果key过期后,会自动删除
- -1 #返回值表示永不过期,默认创建的key是永不过期,重新对key赋值,也会从有剩余生命周期变成永不过期
- -2 #返回值表示没有此key
- num #key的剩余有效期
- ttl key #查看key的剩余生存时间,如果key过期后,会自动删除
127.0.0.1:6379> ttl age
(integer) -2
127.0.0.1:6379> ttl name
(integer) -2
127.0.0.1:6379> set name eagle ex 20
OK
127.0.0.1:6379> ttl name
(integer) 18
127.0.0.1:6379> ttl k1
(integer) -1
- 重新设置key的过期时间
127.0.0.1:6379> set name eagle ex 20
OK
127.0.0.1:6379> expire name 30
(integer) 1
127.0.0.1:6379> ttl name
(integer) 29
- 取消key的过期时间
127.0.0.1:6379> ttl name
(integer) 5
127.0.0.1:6379> persist name
(integer) 1
127.0.0.1:6379> ttl name
(integer) -1
- 数值递增
- 利用INCR命令簇(INCR, DECR, [INCRBY],DECRBY)来把字符串当作原子计数器使用
127.0.0.1:6379> set num 21
OK
127.0.0.1:6379> incr num
(integer) 22
127.0.0.1:6379> get num
"22"
- 数值递减
127.0.0.1:6379> set num 21
OK
127.0.0.1:6379> decr num
(integer) 20
127.0.0.1:6379> get num
"20"
- 数值增加
将key对应的数字加decrement(可以是负数)。如果key不存在,操作之前,key就会被置为0。如果key的value类型错误或者是个不能表示成数字的字符串,就返回错误。这个操作最多支持64位有符号的正型数字。
127.0.0.1:6379> set num 30
OK
127.0.0.1:6379> incrby num 20
(integer) 50
127.0.0.1:6379> get num
"50"
127.0.0.1:6379> incrby num -20
(integer) 30
127.0.0.1:6379> get num
"30"
127.0.0.1:6379> get num1
(nil)
127.0.0.1:6379> incrby num1 5
(integer) 5
127.0.0.1:6379> get num1
"5"
列表 list

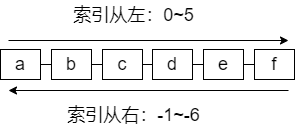
列表是一个双向可读写的管道,其头部是左侧,尾部是右侧,一个列表最多可以包含2^32-1(4294967295)个元素,下标 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。
也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,元素值可以重复,常用于存入日志等场景,此数据类型比较常用
- 列表特点:
- 有序
- 可重复
- 左右都可以操作
- 生成列表并插入数据
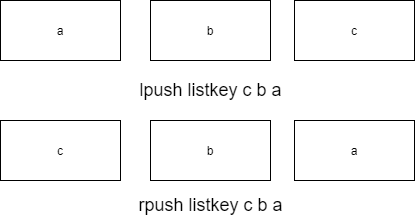
- LPUSH和RPUSH都可以插入列表
127.0.0.1:6379> lpush name eagle cs xwz tj
(integer) 4
127.0.0.1:6379> type name
list
127.0.0.1:6379> rpush course linux python go
(integer) 3
127.0.0.1:6379> type course
list
- 向列表追加数据
127.0.0.1:6379> lpush name abc
(integer) 5
127.0.0.1:6379> rpush name tom
(integer) 6
- 获取列表长度(元素个数)
127.0.0.1:6379> llen name
(integer) 6
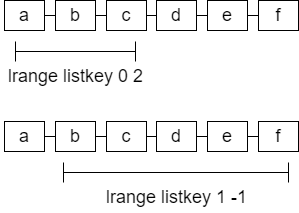
- 获取列表指定位置数据
127.0.0.1:6379> lpush list1 a b c d
(integer) 4
127.0.0.1:6379> lindex list1 0 #获取0编号的元素
"d"
127.0.0.1:6379> lindex list1 3 #获取3编号的元素
"a"
127.0.0.1:6379> lindex list1 -1 #获取最后一个的元素
"a"
127.0.0.1:6379> lrange list1 1 2
1) "c"
2) "b"
127.0.0.1:6379> lrange list1 0 3 #所有元素
1) "d"
2) "c"
3) "b"
4) "a"
127.0.0.1:6379> lrange list1 0 -1 #所有元素
1) "d"
2) "c"
3) "b"
4) "a"
- 修改列表指定索引值
127.0.0.1:6379> lrange list1 0 -1
1) "d"
2) "c"
3) "b"
4) "a"
127.0.0.1:6379> rpush listkey a b c d e f
(integer) 6
127.0.0.1:6379> lrange listkey 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
127.0.0.1:6379> lset listkey 2 redis
OK
127.0.0.1:6379> lrange listkey 0 -1
1) "a"
2) "b"
3) "redis"
4) "d"
5) "e"
6) "f"
- 移除列表数据
127.0.0.1:6379> lpush list1 a b c d
(integer) 4
127.0.0.1:6379> lrange list1 0 3
1) "d"
2) "c"
3) "b"
4) "a"
127.0.0.1:6379> lpop list1 #弹出左边第一个元素,即删除第一个
"d"
127.0.0.1:6379> rpop list1 #弹出右边第一个元素,即删除最后一个
"a"
127.0.0.1:6379> llen list1
(integer) 2
127.0.0.1:6379> lrange list1 0 -1
1) "c"
2) "b"
* LTRIM 对一个列表进行修剪(trim),让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除
127.0.0.1:6379> lrange list1 0 3
1) "d"
2) "c"
3) "b"
4) "a"
127.0.0.1:6379> ltrim list1 1 2
OK
127.0.0.1:6379> lrange list1 0 -1
1) "c"
2) "b"
- 删除list
127.0.0.1:6379> del list1
(integer) 1
127.0.0.1:6379> exists list1
(integer) 0
集合 set
Set 是 String 类型的无序集合,集合中的成员是唯一的,这就意味着集合中不能出现重复的数据,可以在两个不同的集合中对数据进行对比并取值,常用于取值判断,统计,交集等场景
- 集合特点
- 无序
- 无重复
- 集合间操作
- 生成集合key
127.0.0.1:6379> sadd set1 v1
(integer) 1
127.0.0.1:6379> sadd set2 v2 v3
(integer) 2
127.0.0.1:6379> type set1
set
127.0.0.1:6379> type set2
set
- 追加数值
- 追加时,只能追加不存在的数据,不能追加已经存在的数据
127.0.0.1:6379> sadd set1 v1 #已存在的值,无法再次添加
(integer) 0
127.0.0.1:6379> sadd set1 v3 v4 v5
(integer) 3
- 查看集合的所有数据
127.0.0.1:6379> smembers set1
1) "v3"
2) "v5"
3) "v4"
4) "v1"
127.0.0.1:6379> smembers set2
1) "v3"
2) "v2"
- 删除集合中的元素
127.0.0.1:6379> sadd goods mobile car laptop
(integer) 3
127.0.0.1:6379> srem goods car
(integer) 1
127.0.0.1:6379> smembers goods
1) "mobile"
2) "laptop"
- 获取集合的交集
- 交集:已属于A且属于B的元素称为A与B的交集
127.0.0.1:6379> smembers set1
1) "v3"
2) "v5"
3) "v4"
4) "v1"
127.0.0.1:6379> smembers set2
1) "v3"
2) "v2"
127.0.0.1:6379> sinter set1 set2
1) "v3"
- 获取集合的并集
- 并集:已属于A或属于B的元素称为A与B的并集
127.0.0.1:6379> sunion set1 set2
1) "v1"
2) "v4"
3) "v5"
4) "v3"
5) "v2"
- 获取集合的差集
- 差集:已属于A而不属于B的元素称为A与B的差(集)
127.0.0.1:6379> sdiff set1 set2
1) "v1"
2) "v4"
3) "v5"
有序集合 sorted set
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个double(双精度浮点型)类型的分数,redis正是通过该分数来为集合中的成员进行从小到大的排序,有序集合的成员是唯一的,但分数(score)却可以重复,集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1), 集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员),经常用于排行榜的场景
- 有序集合特点
- 有序
- 无重复元素
- 每个元素是由score和value组成
- score 可以重复
- value 不可以重复
- 生成有序集合
127.0.0.1:6379> zadd zset1 1 v1 #分数为1
(integer) 1
127.0.0.1:6379> zadd zset1 2 v2
(integer) 1
127.0.0.1:6379> zadd zset1 2 v3 #分数可重复,元素值不可以重复
(integer) 1
127.0.0.1:6379> zadd zset1 3 v4
(integer) 1
127.0.0.1:6379> type zset1
zset
127.0.0.1:6379> zadd zset2 1 v1 2 v2 3 v3 4 v4 5 v5 #一次生成多个数据
(integer) 5
- 有序集合实现排行榜
127.0.0.1:6379> zadd phb 90 xls 95 tj 30 sg
(integer) 3
127.0.0.1:6379> zrange phb 0 -1
#正序排序后显示集合内所有的key,score从小到大显示
1) "sg"
2) "xls"
3) "tj"
127.0.0.1:6379> zrevrange phb 0 -1
#倒叙排序后显示集合内所有的key,score从大到小显示
1) "tj"
2) "xls"
3) "sg"
127.0.0.1:6379> zrevrange phb 0 -1 withscores
#正序显示指定集合内所有key和得分情况
1) "tj"
2) "95"
3) "xls"
4) "90"
5) "sg"
6) "30"
- 获取集合的个数
127.0.0.1:6379> zcard phb
(integer) 3
- 基于索引返回数值
127.0.0.1:6379> zrange phb 0 2
1) "sg"
2) "xls"
3) "tj"
127.0.0.1:6379> zrange phb 0 -1
1) "sg"
2) "xls"
3) "tj"
- 返回某个数值的索引(排名)
127.0.0.1:6379> zadd phb 90 xls 95 tj 30 sg
(integer) 3
127.0.0.1:6379> zrange phb 0 -1
1) "sg"
2) "xls"
3) "tj"
127.0.0.1:6379> zrank phb sg
(integer) 0
127.0.0.1:6379> zrank phb tj
(integer) 2
- 获取分数
127.0.0.1:6379> zscore phb tj
"95"
127.0.0.1:6379> zscore phb sg
"30"
- 删除元素
127.0.0.1:6379> zrem phb sg tj
(integer) 2
127.0.0.1:6379> zrange phb 0 -1
1) "xls"
哈希 hash
hash 是一个string类型的字段(field)和值(value)的映射表,Redis 中每个 hash 可以存储 2^32 -1 键值对,类似于字典,存放了多个k/v 对,hash特别适合用于存储对象场景
- 生成 hash key
127.0.0.1:6379> hset 9527 name sg age 30
(integer) 2
127.0.0.1:6379> type 9527
hash
127.0.0.1:6379> hgetall 9527
1) "name"
2) "sg"
3) "age"
4) "30"
#增加字段
127.0.0.1:6379> hset 9527 gender man
(integer) 1
127.0.0.1:6379> hgetall 9527
1) "name"
2) "sg"
3) "age"
4) "30"
5) "gender"
6) "man"
- 获取hash key的对应字段的值
127.0.0.1:6379> hget 9527 name
"sg"
127.0.0.1:6379> hget 9527 gender
"man"
127.0.0.1:6379> hmget 9527 age gender #获取多个值
1) "30"
2) "man"
- 删除一个hash key 的对应字段
127.0.0.1:6379> hdel 9527 age
(integer) 1
127.0.0.1:6379> hget 9527 age
(nil)
- 批量设置hash key的多个field和value
127.0.0.1:6379> hmset 1024 name xwz age 18 city changzhou
OK
127.0.0.1:6379> hgetall 1024
1) "name"
2) "xwz"
3) "age"
4) "18"
5) "city"
6) "changzhou"
- 获取hash中指定字段的值
127.0.0.1:6379> hmget 1024 name city
1) "xwz"
2) "changzhou"
- 获取hash中的所有字段名field
127.0.0.1:6379> hkeys 1024
1) "name"
2) "age"
3) "city"
- 获取hash key对应所有field的value
127.0.0.1:6379> hvals 1024
1) "xwz"
2) "18"
3) "changzhou"
- 获取指定hash key 的所有field及value
127.0.0.1:6379> hgetall 1024
1) "name"
2) "xwz"
3) "age"
4) "18"
5) "city"
6) "changzhou"
- 删除 hash
127.0.0.1:6379> del 1024
(integer) 1
127.0.0.1:6379> hmget 1024 name age
1) (nil)
2) (nil)
127.0.0.1:6379> exists 1024
(integer) 0
消息队列
- 消息队列: 把要传输的数据放在队列中
- 功能: 可以实现多个系统之间的解耦,异步,削峰/限流等
- 常用的消息队列应用: kafka,rabbitMQ,redis
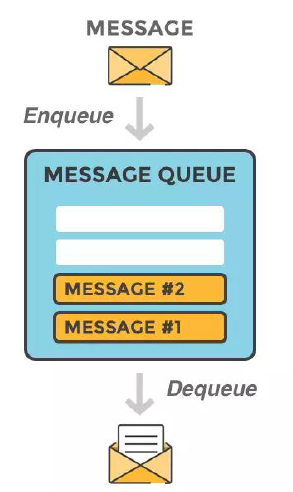
消息队列主要分为两种,这两种模式Redis都支持
- 生产者/消费者模式
- 发布者/订阅者模式
生产者消费者模式
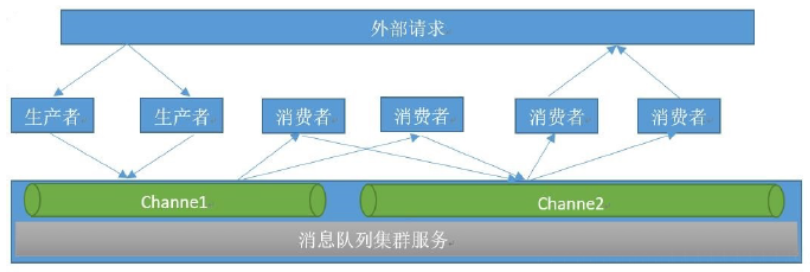
在生产者/消费者(Producer/Consumer)模式下,上层应用接收到的外部请求后开始处理其当前步骤的操作,在执行完成后将已经完成的操作发送至指定的频道(channel,逻辑队列)当中,并由其下层的应用监听该频道并继续下一步的操作,如果其处理完成后没有下一步的操作就直接返回数据给外部请求,如果还有下一步的操作就再将任务发布到另外一个频道,由另外一个消费者继续监听和处理。此模式应用广泛
模式介绍
生产者消费者模式下,多个消费者同时监听一个队列,但是一个消息只能被最先抢到消息的消费者消费,即消息任务是一次性读取和处理,此模式在分布式业务架构中很常用,比较常用的消息队列软件还有RabbitMQ、Kafka、RocketMQ、ActiveMQ等。
队列介绍
队列当中的消息由不同的生产者写入,也会有不同的消费者取出进行消费处理,但是一个消息一定是只能被取出一次也就是被消费一次。
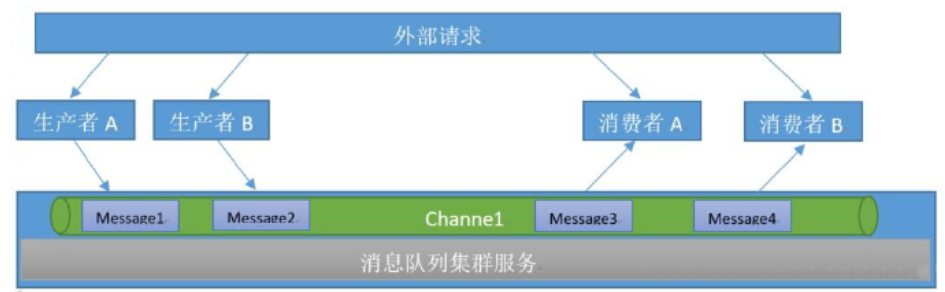
- 生产者发布消息
[root@localhost ~]# redis-cli
127.0.0.1:6379> auth centos
OK
127.0.0.1:6379> lpush channel1 msg1
(integer) 1
127.0.0.1:6379> lpush channel1 msg2
(integer) 2
127.0.0.1:6379> lpush channel1 msg3
(integer) 3
127.0.0.1:6379> lpush channel1 msg4
(integer) 4
127.0.0.1:6379> lpush channel1 msg5
(integer) 5
- 查看队列所有消息
127.0.0.1:6379> lrange channel1 0 -1
1) "msg5"
2) "msg4"
3) "msg3"
4) "msg2"
5) "msg1"
- 消费者消费消息
127.0.0.1:6379> rpop channel1
"msg1"
127.0.0.1:6379> rpop channel1
"msg2"
127.0.0.1:6379> rpop channel1
"msg3"
127.0.0.1:6379> rpop channel1
"msg4"
127.0.0.1:6379> rpop channel1
"msg5"
127.0.0.1:6379> rpop channel1
(nil)
发布者订阅模式
模式简介
在发布者订阅者模式下,发布者将消息发布到指定的channel里面,凡是监听该channel的消费者都会收到同样的一份消息,这种模式类似于是收音机的广播模式,即凡是收听某个频道的听众都会收到主持人发布的相同的消息内容。此模式常用于群聊天、群通知、群公告等场景
- Publisher:发布者
- Subscriber:订阅者
- Channel:频道
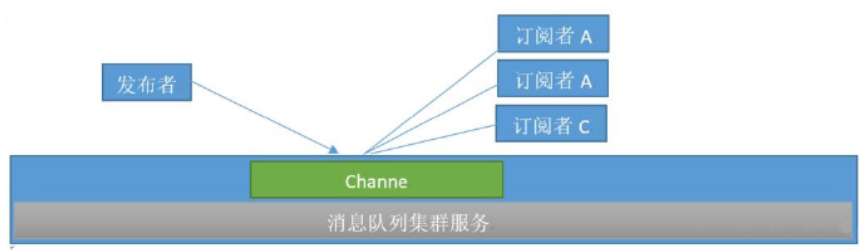
- 订阅者监听频道
127.0.0.1:6379> subscribe channel1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
3) (integer) 1
- 发布者发布消息
127.0.0.1:6379> publish channel1 test1
(integer) 1 #订阅者个数
127.0.0.1:6379> publish channel1 test2
(integer) 1
- 各个订阅者都能收到消息
127.0.0.1:6379> subscribe channel1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
3) (integer) 1
1) "message"
2) "channel1"
3) "test1"
1) "message"
2) "channel1"
3) "test2"
- 订阅多个频道
127.0.0.1:6379> subscribe channel1 channel2
- 订阅所有频道
127.0.0.1:6379> psubscribe * #支持通配符*
- 订阅匹配的频道
127.0.0.1:6379> PSUBSCRIBE chann* #匹配订阅多个频道
- 取消订阅
127.0.0.1:6379> unsubscribe channel1
1) "unsubscribe"
2) "channel1"
3) (integer) 0
redis 主从复制
虽然Redis可以实现单机的数据持久化,但无论是RDB也好或者AOF也好,都解决不了单点宕机问题,即一旦单台 redis服务器本身出现系统故障、硬件故障等问题后,就会直接造成数据的丢失
此外,单机的性能也是有极限的,因此需要使用另外的技术来解决单点故障和性能扩展的问题。
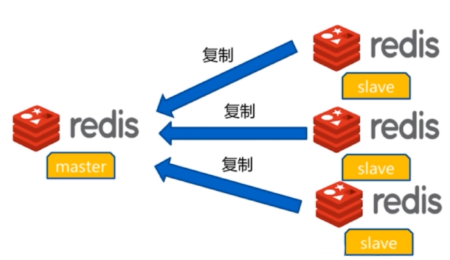
redis 主从复制架构
主从模式(master/slave),可以实现Redis数据的跨主机备份。
程序端连接到高可用负载的VIP,然后连接到负载服务器设置的Redis后端real server,此模式不需要在程序里面配置Redis服务器的真实IP地址,当后期Redis服务器IP地址发生变更只需要更改redis 相应的后端real server即可, 可避免更改程序中的IP地址设置。
- 一个master可以有多个slave
- 一个slave只能有一个master
- 数据流向是单向的,master到slave
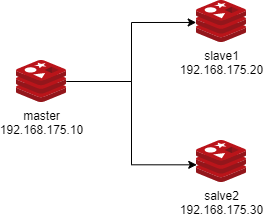
主从复制实现
Redis Slave 也要开启持久化并设置和master同样的连接密码,因为后期slave会有提升为master的可能,Slave 端切换master同步后会丢失之前的所有数据,而通过持久化可以恢复数据
一旦某个Slave成为一个master的slave,Redis Slave服务会清空当前redis服务器上的所有数据并将master的数据导入到自己的内存,但是如果只是断开同步关系后,则不会删除当前已经同步过的数据。
当配置Redis复制功能时,强烈建议打开主服务器的持久化功能。否则的话,由于延迟等问题,部署的服务应该要避免自动启动。
- 假设节点A为主服务器,并且关闭了持久化。并且节点B和节点c从节点A复制数据
- 节点A崩溃,然后由自动拉起服务重启了节点A.由于节点A的持久化被关闭了,所以重启之后没有任何数据
- 节点B和节点c将从节点A复制数据,但是A的数据是空的,于是就把自身保存的数据副本删除。
在关闭主服务器上的持久化,并同时开启自动拉起进程的情况下,即便使用Sentinel来实现Redis的高可用性,也是非常危险的。因为主服务器可能拉起得非常快,以至于Sentinel在配置的心跳时间间隔内没有检测到主服务器已被重启,然后还是会执行上面的数据丢失的流程。无论何时,数据安全都是极其重要的,所以应该禁止主服务器关闭持久化的同时自动启动。
命令行配置
- 启用主从同步
- 默认redis 状态为master,需要转换为slave角色并指向master服务器的IP+PORT+Password
- REPLICAOF MASTER_IP PORT 指令可以启用主从同步复制功能,早期版本使用 SLAVEOF 指令
- 在master上设置key1
[root@master ~]# redis-cli -a centos
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_replid:75166c08ad870d6eaa5c27e003bc2b36488a3cae
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> set key1 v1-master
OK
127.0.0.1:6379> keys *
1) "key1"
127.0.0.1:6379> get key1
"v1-master"
- 以下都在slave上执行,登录,设置key1
[root@slave1 ~]# redis-cli -a centos --no-auth-warning
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_replid:1a274a8475450314d9ebb232717fa6cc3720e62f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> set key1 v1-slave1
OK
127.0.0.1:6379> keys *
1) "key1"
127.0.0.1:6379> get key1
"v1-slave1"
- 在第二个slave2上,也设置相同的key1,但值不同
[root@slave2 ~]# redis-cli -a centos --no-auth-warning
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_replid:2b8d846c9f01eea950100d75caf1e8e3600a8d4a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> set key1 v1-slave2
OK
127.0.0.1:6379> keys *
1) "key1"
127.0.0.1:6379> get key1
"v1-slave2"
- 在所有的slave上设置master的IP和端口,4.0版本之前的指令为slaveof
- 在slave1上
127.0.0.1:6379> replicaof 192.168.175.10 6379
# 仍可使用SLAVEOF MasterIP Port
OK
127.0.0.1:6379> config set masterauth centos
#在slave上设置master的密码,才可以同步
OK
127.0.0.1:6379> info replication
# Replication
role:slave #角色变为slave
master_host:192.168.175.10 #指向master
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:0
master_link_down_since_seconds:1625794777
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:1a274a8475450314d9ebb232717fa6cc3720e62f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> get key1
# 查看数据是否同步成功
"v1-master"
* 在slave2上
127.0.0.1:6379> replicaof 192.168.175.10 6379
OK
127.0.0.1:6379> config set masterauth centos
OK
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.10
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:0
master_link_down_since_seconds:1625794971
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:2b8d846c9f01eea950100d75caf1e8e3600a8d4a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> get key1
"v1-master"
- 在master上可以看到所有slave的信息
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.175.30,port=6379,state=online,offset=224,lag=1
slave1:ip=192.168.175.20,port=6379,state=online,offset=224,lag=0
master_replid:d6f1142f22e456f4e4093fcb81648cab127ebc7f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:224
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:224
- 删除主从同步
- REPLICAOF NO ONE 指令可以取消主从复制
127.0.0.1:6379> replicaof no one
OK
127.0.0.1:6379> info replication
# Replication
role:master #角色变回了master
connected_slaves:0
master_replid:9507932f3addde3a76b51c5d6ecbb5daac398caa
master_replid2:f68659a5c6e8381dbbdd6841f5b89d1a60157af8
master_repl_offset:1064
second_repl_offset:1065
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1064
- 在master上看到slave数量减少
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
同步日志
- 在 master 上观察日志
[root@master ~]# tail /apps/redis/log/redis_6379.log
6815:M 09 Jul 2021 09:44:03.398 * Synchronization with replica 192.168.175.20:6379 succeeded
6815:M 09 Jul 2021 09:53:26.312 # Connection with replica 192.168.175.20:6379 lost.
6815:M 09 Jul 2021 09:54:04.298 * Replica 192.168.175.20:6379 asks for synchronization
6815:M 09 Jul 2021 09:54:04.298 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '2feb7cc9c49ff2a52f4749a0cd26218d9ca6577a', my replication IDs are 'd6f1142f22e456f4e4093fcb81648cab127ebc7f' and '0000000000000000000000000000000000000000')
6815:M 09 Jul 2021 09:54:04.298 * Starting BGSAVE for SYNC with target: disk
6815:M 09 Jul 2021 09:54:04.299 * Background saving started by pid 7234
7234:C 09 Jul 2021 09:54:04.300 * DB saved on disk
7234:C 09 Jul 2021 09:54:04.300 * RDB: 0 MB of memory used by copy-on-write
6815:M 09 Jul 2021 09:54:04.394 * Background saving terminated with success
6815:M 09 Jul 2021 09:54:04.395 * Synchronization with replica 192.168.175.20:6379 succeeded
- 在 slave 节点观察日志
[root@slave2 ~]# tail /apps/redis/log/redis_6379.log
6838:S 09 Jul 2021 09:44:02.914 * MASTER <-> REPLICA sync started
6838:S 09 Jul 2021 09:44:02.914 * Non blocking connect for SYNC fired the event.
6838:S 09 Jul 2021 09:44:02.915 * Master replied to PING, replication can continue...
6838:S 09 Jul 2021 09:44:02.916 * Trying a partial resynchronization (request 2b8d846c9f01eea950100d75caf1e8e3600a8d4a:1).
6838:S 09 Jul 2021 09:44:02.918 * Full resync from master: d6f1142f22e456f4e4093fcb81648cab127ebc7f:0
6838:S 09 Jul 2021 09:44:02.918 * Discarding previously cached master state.
6838:S 09 Jul 2021 09:44:02.992 * MASTER <-> REPLICA sync: receiving 196 bytes from master
6838:S 09 Jul 2021 09:44:02.993 * MASTER <-> REPLICA sync: Flushing old data
6838:S 09 Jul 2021 09:44:02.993 * MASTER <-> REPLICA sync: Loading DB in memory
6838:S 09 Jul 2021 09:44:02.993 * MASTER <-> REPLICA sync: Finished with success
修改slave节点配置文件
- 在slave1上
[root@slave1 ~]# grep replicaof /apps/redis/etc/redis.conf
# Master-Replica replication. Use replicaof to make a Redis instance a copy of
# replicaof <masterip> <masterport>
[root@slave1 ~]# echo "replicaof 192.168.175.10 6379" >> /apps/redis/etc/redis.conf
[root@slave1 ~]# echo "masterauth centos" >> /apps/redis/etc/redis.conf
[root@slave1 ~]# systemctl restart redis
- 在slave2上
[root@slave2 ~]# echo "replicaof 192.168.175.10 6379" >> /apps/redis/etc/redis.conf
[root@slave2 ~]# echo "masterauth centos" >> /apps/redis/etc/redis.conf
[root@slave2 ~]# systemctl restart redis
- master和slave查看状态
# 在master上
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.175.20,port=6379,state=online,offset=4452,lag=1
slave1:ip=192.168.175.30,port=6379,state=online,offset=4452,lag=1
# 在slave1上
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.10
master_port:6379
127.0.0.1:6379> get key1
"v1-master"
#在slave2上
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.10
master_port:6379
127.0.0.1:6379> get key1
"v1-master"
- 停止master的redis服务:systemctl stop redis,在slave上可以看到以下现象
# 在master上停止服务
[root@master ~]# systemctl stop redis
#在slave上可以看到
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.10
master_port:6379
master_link_status:down #显示down,表示无法连接master
- slave 观察日志
[root@slave1 ~]# tail /apps/redis/log/redis_6379.log
15506:S 09 Jul 2021 10:41:56.295 # Error condition on socket for SYNC: Connection refused
15506:S 09 Jul 2021 10:41:57.311 * Connecting to MASTER 192.168.175.10:6379
15506:S 09 Jul 2021 10:41:57.311 * MASTER <-> REPLICA sync started
15506:S 09 Jul 2021 10:41:57.311 # Error condition on socket for SYNC: Connection refused
15506:S 09 Jul 2021 10:41:58.333 * Connecting to MASTER 192.168.175.10:6379
15506:S 09 Jul 2021 10:41:58.333 * MASTER <-> REPLICA sync started
15506:S 09 Jul 2021 10:41:58.334 # Error condition on socket for SYNC: Connection refused
15506:S 09 Jul 2021 10:41:59.359 * Connecting to MASTER 192.168.175.10:6379
15506:S 09 Jul 2021 10:41:59.359 * MASTER <-> REPLICA sync started
15506:S 09 Jul 2021 10:41:59.360 # Error condition on socket for SYNC: Connection refused
- slave 状态只读无法写入数据
127.0.0.1:6379> set key1 v1-slave1
(error) READONLY You can't write against a read only replica.
主从复制故障恢复
主从复制故障恢复过程介绍
- slave 节点故障和恢复
- client指向另一个从节点即可,并及时修复故障从节点
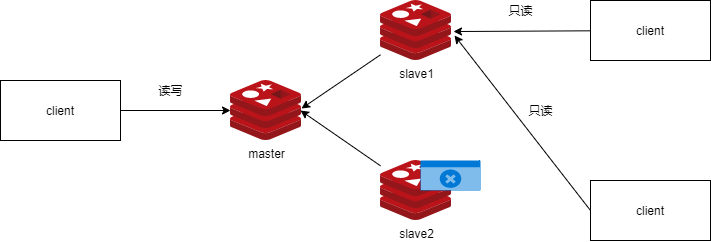
- master 节点故障和恢复
- 需要提升slave为新的master
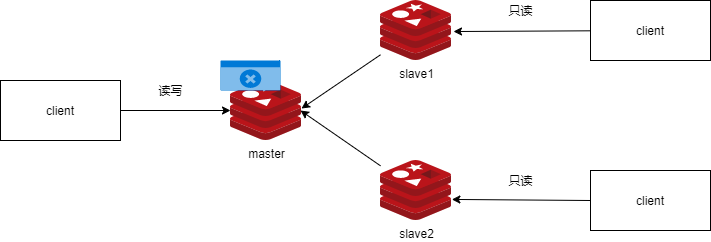

- master故障后,只能手动提升一个slave为新master,不支持自动切换。master的切换会导致master_replid发生变化,slave之前的master_replid就和当前master不一致从而会引发所有slave的全量同步
主从复制故障恢复实现
- 假设当前主节点192.168.175.10故障,提升192.168.175.20为新的master
[root@master ~]# systemctl stop redis
- 查看slave1
[root@slave1 ~]# redis-cli -a centos --no-auth-warning
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.10
master_port:6379
master_link_status:down
- 停止slave1(192.168.175.20)同步并提升为新的master
127.0.0.1:6379> replicaof no one
OK
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_replid:46804bd951a74f28dbd453d4cab68ca6fbd2e6bc
master_replid2:d6f1142f22e456f4e4093fcb81648cab127ebc7f
master_repl_offset:4648
second_repl_offset:4649
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:827
repl_backlog_histlen:3822
127.0.0.1:6379> set keytest1 vtest1
OK
- 修改所有的slave指向新的master节点
127.0.0.1:6379> replicaof 192.168.175.20 6379
OK
127.0.0.1:6379> config set masterauth centos
OK
127.0.0.1:6379> set key100 v100
(error) READONLY You can't write against a read only replica.
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.20
master_port:6379
master_link_status:up
127.0.0.1:6379> get keytest1
"vtest1"
- 在新master(192.168.175.20)上可看到slave
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.175.30,port=6379,state=online,offset=4836,lag=1
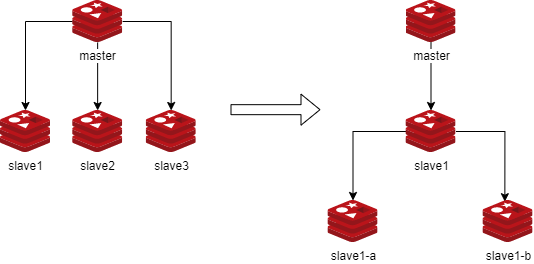
实现redis的级联复制

在前面搭建好的一主一从架构中,master和slave1节点无需修改,只需要修改slave2及slave3指向slave1作为master即可
[root@slave2 ~]# redis-cli -a centos
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> REPLICAOF 192.168.175.20 6379
OK
127.0.0.1:6379> config set masterauth centos
OK
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.20
master_port:6379
[root@slave3 ~]# redis-cli -a centos
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> replicaof 192.168.175.20 6379
OK
127.0.0.1:6379> config set masterauth centos
OK
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.20
master_port:6379
- 在master上设置key,观察是否同步
# master设置key
127.0.0.1:6379> set name eagle
OK
127.0.0.1:6379> get name
"eagle"
#在slave上验证key
127.0.0.1:6379> get name
"eagle"
- 在中间那个slave(即级联salve1 192.168.175.20)上查看状态
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.10
master_port:6379
master_link_status:up
master_last_io_seconds_ago:9 #最近一次与master通信已经过去多少秒
master_sync_in_progress:0 #是否正在与master通信
slave_repl_offset:799 #当前同步的偏移量
slave_priority:100 #slave优先级,master故障后优先级值越小越优先同步
slave_read_only:1
connected_slaves:2
slave0:ip=192.168.175.30,port=6379,state=online,offset=799,lag=0
slave1:ip=192.168.175.40,port=6379,state=online,offset=799,lag=0
master_replid:e262f6e6fdd1d02222afc48ade1860163e3c096b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:799
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:799
主从复制优化
主从复制过程
Redis主从复制分为全量同步和增量同步
- 全量复制过程
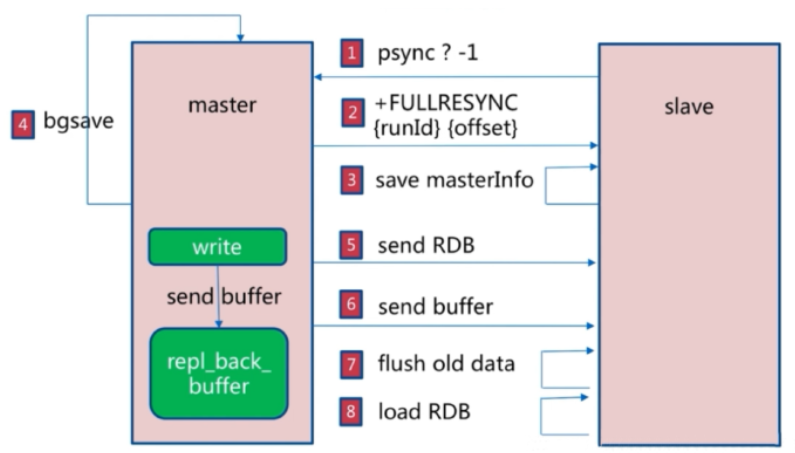
首次同步是全量同步,主从同步可以让从服务器从主服务器同步数据,而且从服务器还可再有其它的从服务器,即另外一台redis服务器可以从一台从服务器进行数据同步,redis 的主从同步是非阻塞的,master收到从服务器的psync(2.8版本之前是SYNC)命令,会fork一个子进程在后台执行bgsave命令,并将新写入的数据写入到一个缓冲区中,bgsave执行完成之后,将生成的RDB文件发送给slave,然后master再将缓冲区的内容以redis协议格式再全部发送给slave,slave 先删除旧数据,slave将收到后的RDB文件载入自己的内存,再加载所有收到缓冲区的内容 从而这样一次完整的数据同步
Redis全量复制一般发生在Slave首次初始化阶段,这时Slave需要将Master上的所有数据都复制一份。
- 增量复制过程
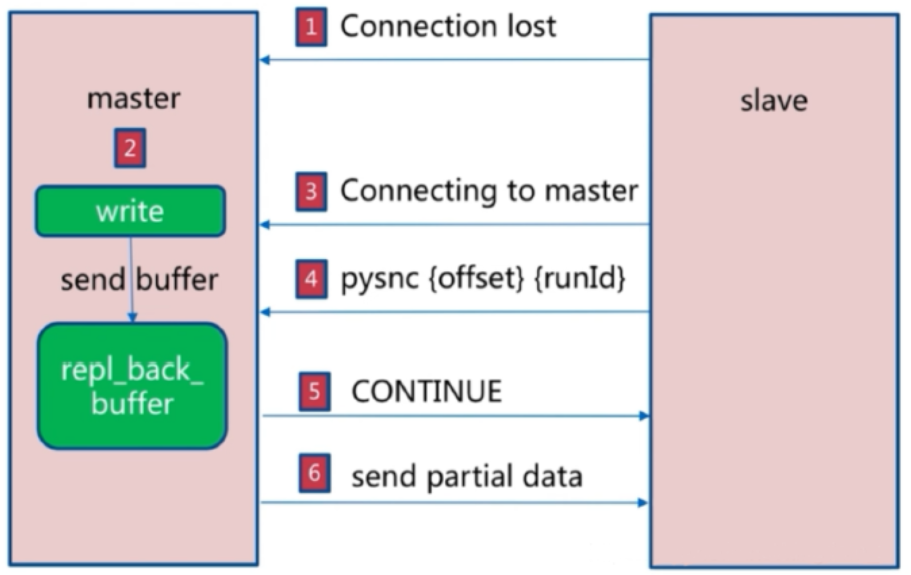
全量同步之后再次需要同步时,从服务器只要发送当前的offset位置(等同于MySQL的binlog的位置)给主服务器,然后主服务器根据相应的位置将之后的数据(包括写在缓冲区的积压数据)发送给从服务器,其再次保存到其内存即可。
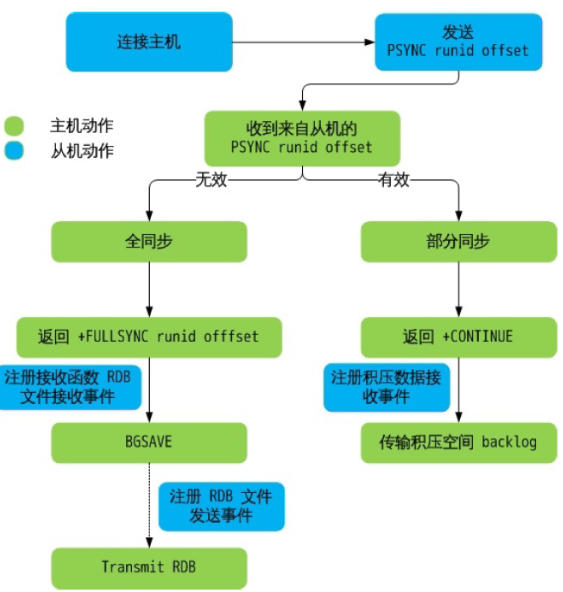
- 主从同步完整过程
- 从服务器连接主服务器,发送PSYNC命令
- 主服务器接收到PSYNC命令后,开始执行BGSAVE命令生成RDB快照文件并使用缓冲区记录此后执行的所有写命令
- 主服务器BGSAVE执行完后,向所有从服务器发送RDB快照文件,并在发送期间继续记录被执行的写命令
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照至内存
- 主服务器快照发送完毕后,开始向从服务器发送缓冲区中的写命令
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令
- 后期同步会先发送自己slave_repl_offset位置,只同步新增加的数据,不再全量同步
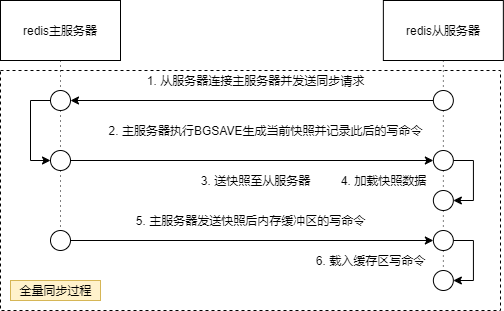

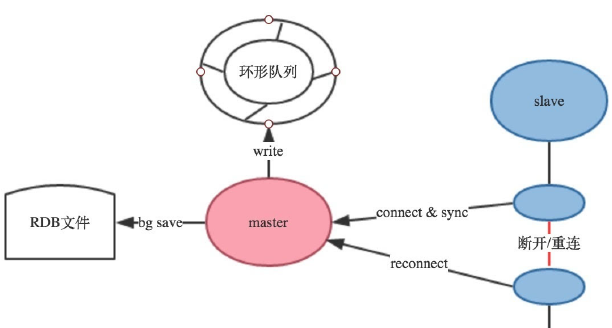
- 复制缓冲区(环形队列)配置参数
#复制缓冲区大小,建议要设置足够大
rep-backlog-size 1mb
#Redis同时也提供了当没有slave需要同步的时候,多久可以释放环形队列:
repl-backlog-ttl 3600
- 避免全量复制
- 第一次全量复制不可避免,后续的全量复制可以利用小主节点(内存小),业务低峰时进行全量
- 节点运行 run-id 不匹配:主节点重启会导致RUNID变化,可能会触发全量复制,可以利用故障转移,例如哨兵或集群,而从节点重新启动,不会导致全量复制
- 复制积压缓冲区不足: 当主节点生成的新数据大于缓冲区大小,从节点恢复和主节点连接后,会导致全量复制.解决方法将repl-backlog-size 调大
- 避免复制风暴
- 单节点复制风暴
- 当主节点重启,多从节点复制
- 解决方法:更换复制拓扑
- 单节点复制风暴
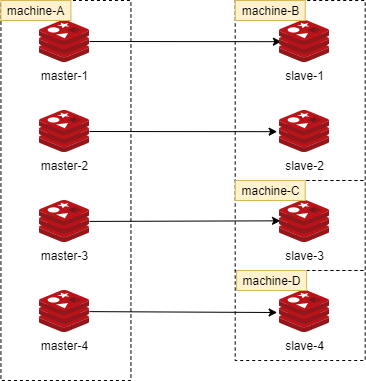
- 单机器复制风暴
- 机器宕机后,大量全量复制
- 解决方法:主节点分散多机器
主从同步优化配置
Redis在2.8版本之前没有提供增量部分复制的功能,当网络闪断或者slave Redis重启之后会导致主从之间的全量同步,即从2.8版本开始增加了部分复制的功能。
- 性能相关配置
repl-diskless-sync no # 是否使用无盘同步RDB文件,默认为no,no为不使用无盘,需要将RDB文件保存到磁盘后再发送给slave,yes为支持无盘,支持无盘就是RDB文件不需要保存至本地磁盘,而且直接通过socket文件发送给slave
repl-diskless-sync-delay 5 #diskless时复制的服务器等待的延迟时间
repl-ping-slave-period 10 #slave端向server端发送ping的时间间隔,默认为10秒
repl-timeout 60 #设置主从ping连接超时时间,超过此值无法连接,master_link_status显示为down,并记录错误日志
repl-disable-tcp-nodelay no #是否启用TCP_NODELAY,如设置成yes,则redis会合并小的TCP包从而节省带宽, 但会增加同步延迟(40ms),造成master与slave数据不一致,假如设置成no,则redismaster会立即发送同步数据,没有延迟,yes关注性能,no关注redis服务中的数据一致性
repl-backlog-size 1mb #master的写入数据缓冲区,用于记录自上一次同步后到下一次同步过程中间的写入命令,计算公式:repl-backlog-size = 允许从节点最大中断时长 * 主实例offset每秒写入量,比如master每秒最大写入64mb,最大允许60秒,那么就要设置为64mb*60秒=3840MB(3.8G),建议此值是设置的足够大
repl-backlog-ttl 3600 #如果一段时间后没有slave连接到master,则backlog size的内存将会被释放。如果值为0则表示永远不释放这部份内存。
slave-priority 100 #slave端的优先级设置,值是一个整数,数字越小表示优先级越高。当master故障时将会按照优先级来选择slave端进行恢复,如果值设置为0,则表示该slave永远不会被选择。
min-replicas-to-write 1 #设置一个master的可用slave不能少于多少个,否则master无法执行写
min-slaves-max-lag 20 #设置至少有上面数量的slave延迟时间都大于多少秒时,master不接收写操作(拒绝写入)
常见主从复制故障汇总
master密码不对
即配置的master密码不对,导致验证不通过而无法建立主从同步关系。
[root@slave1 ~]#tail -f /var/log/redis/redis.log
3939:S 24 Oct 2020 16:13:57.552 # Server initialized
3939:S 24 Oct 2020 16:13:57.552 * DB loaded from disk: 0.000 seconds
3939:S 24 Oct 2020 16:13:57.552 * Ready to accept connections
3939:S 24 Oct 2020 16:13:57.554 * Connecting to MASTER 10.0.0.18:6379
3939:S 24 Oct 2020 16:13:57.554 * MASTER <-> REPLICA sync started
3939:S 24 Oct 2020 16:13:57.556 * Non blocking connect for SYNC fired the event.
3939:S 24 Oct 2020 16:13:57.558 * Master replied to PING, replication can continue...
3939:S 24 Oct 2020 16:13:57.559 # Unable to AUTH to MASTER: -ERR invalid password
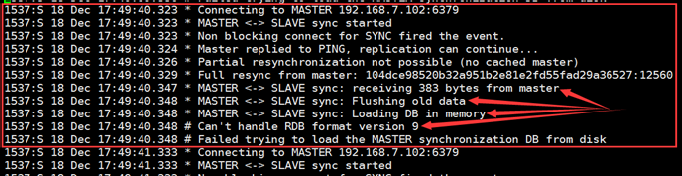
Redis版本不一致
不同的redis 大版本之间存在兼容性问题,比如:3和4,4和5之间,因此各master和slave之间必须保持版本一致
无法远程连接
在开启了安全模式情况下,没有设置bind地址或者密码
[root@slave1 ~]#redis-cli -h 192.168.175.10
192.168.175.10:6379> KEYS *
(error) DENIED Redis is running in protected mode because protected mode is enabled
配置不一致
主从节点的maxmemory不一致,主节点内存大于从节点内存,主从复制可能丢失数据
rename-command 命令不一致,如在主节点定义了fushall,flushdb,从节点没定义,结果执行flushdb,不同步
redis 哨兵(Sentinel)
redis 集群介绍
主从架构无法实现master和slave角色的自动切换,即当master出现redis服务异常、主机断电、磁盘损坏等问题导致master无法使用,而redis主从复制无法实现自动的故障转移(将slave 自动提升为新master),需要手动修改环境配置,才能切换到slave redis服务器,另外也无法横向扩展Redis服务的并行写入性能,当单台Redis服务器性能无法满足业务写入需求的时候,也需要解决以上的两个核心问题
- master和slave角色的无缝切换,让业务无感知从而不影响业务使用
- 可横向动态扩展Redis服务器,从而实现多台服务器并行写入以实现更高并发的目的。
Redis 集群实现方式
- 客户端分片: 由应用决定将不同的KEY发送到不同的Redis服务器
- 代理分片: 由代理决定将不同的KEY发送到不同的Redis服务器,代理程序如:codis,twemproxy等
- Redis Cluster
哨兵 (Sentinel) 工作原理
sentinel 架构和故障转移
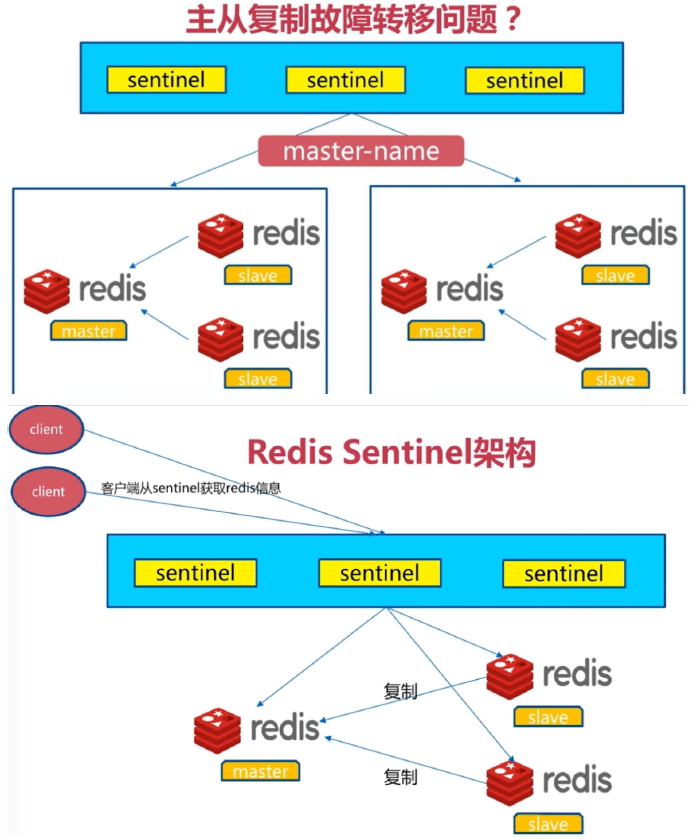
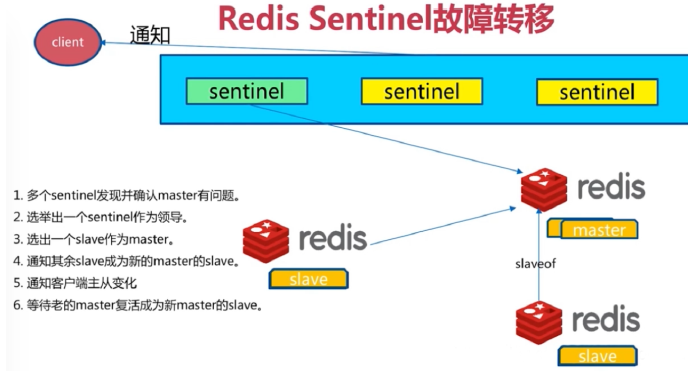
Sentinel 进程是用于监控redis集群中Master主服务器工作的状态,在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用,此功能在redis2.6+的版本已引用,Redis的哨兵模式到了2.8版本之后就稳定了下来。一般在生产环境也建议使用Redis的2.8版本的以后版本
哨兵(Sentinel) 是一个分布式系统,可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议(gossip protocols)来接收关于Master主服务器是否下线的信息,并使用投票协议(Agreement Protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master
每个哨兵(Sentinel)进程会向其它哨兵(Sentinel)、Master、Slave定时发送消息,以确认对方是否”活”着,如果发现对方在指定配置时间(此项可配置)内未得到回应,则暂时认为对方已离线,也就是所谓的”主观认为宕机” (主观:是每个成员都具有的独自的而且可能相同也可能不同的意识),英文名称:Subjective Down,简称SDOWN
有主观宕机,对应的有客观宕机。当“哨兵群”中的多数Sentinel进程在对Master主服务器做出SDOWN的判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,这种方式就是“客观宕机”(客观:是不依赖于某种意识而已经实际存在的一切事物),英文名称是:Objectively Down, 简称 ODOWN
通过一定的vote算法,从剩下的slave从服务器节点中,选一台提升为Master服务器节点,然后自动修改相关配置,并开启故障转移(failover)
Sentinel 机制可以解决master和slave角色的自动切换问题,但单个 Master 的性能瓶颈问题无法解决,类似于MySQL中的MHA功能
Redis Sentinel中的Sentinel节点个数应该为大于等于3且最好为奇数
客户端初始化时连接的是Sentinel节点集合,不再是具体的Redis节点,但Sentinel只是配置中心不是代理。
Redis Sentinel 节点与普通redis 没有区别,要实现读写分离依赖于客户端程序
redis 3.0 之前版本中,生产环境一般使用哨兵模式,但3.0后推出redis cluster功能后,可以支持更大规模的生产环境
sentinel中的三个定时任务
- 每10秒每个sentinel对master和slave执行info
- 发现slave节点
- 确认主从关系
- 每2秒每个sentinel通过master节点的channel交换信息(pub/sub)
- 通过sentinel_hello频道交互
- 交互对节点的“看法”和自身信息
- 每1秒每个sentinel对其他sentinel和redis执行ping
实现哨兵
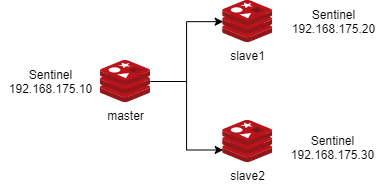
- 哨兵的准备实现主从复制架构
- 哨兵的前提是已经实现了一个redis的主从复制的运行环境,从而实现一个一主两从基于哨兵的高可用redis架构
- 注意: master 的配置文件中masterauth 和slave 都必须相同
# 在所有主从节点执行,这里以master为例
[root@master ~]# vim /apps/redis/etc/redis.conf
bind 0.0.0.0
masterauth "centos"
requirepass centos
[root@master ~]# echo -e "net.core.somaxconn = 1024\nvm.overcommit_memory = 1" >> /etc/sysctl.conf
net.core.somaxconn: 这个参数控制系统同时监听的最大连接数。将其设置为 1024 可以提高系统的并发能力。
vm.overcommit_memory: 这个参数控制内存overcommit策略。设置为 1 表示允许overcommit,即允许进程申请比实际可用内存更多的内存。这在一些内存紧张的场景下会很有用。
[root@master ~]# sysctl -p
net.core.somaxconn = 1024
vm.overcommit_memory = 1
net.core.somaxconn = 1024
vm.overcommit_memory = 1
[root@master ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled
这条命令是用来禁用 Transparent Huge Pages (THP) 功能。
THP 是一种 Linux 内核特性,可以动态合并内存页面以减少页表的数量,从而提高性能。但是在某些场景下它可能会带来副作用,所以需要禁用。
[root@master ~]# echo "echo never > /sys/kernel/mm/transparent_hugepage/enabled" >> /etc/rc.d/rc.local
[root@master ~]# chmod +x /etc/rc.d/rc.local
[root@master ~]# systemctl restart redis
- 设置主从复制
#在所有从节点执行,这里以slave1为例
[root@slave1 ~]# echo "replicaof 192.168.175.10 6379" >> /apps/redis/etc/redis.conf
[root@slave1 ~]# systemctl restart redis
- master服务器状态
[root@master ~]# redis-cli
127.0.0.1:6379> auth centos
OK
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.175.20,port=6379,state=online,offset=112,lag=0
slave1:ip=192.168.175.30,port=6379,state=online,offset=112,lag=0
master_replid:ec21203b0f3034282e18d6532055379b3de45f82
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:112
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:112
- 编辑哨兵的配置文件
- Sentinel实际上是一个特殊的redis服务器,有些redis指令支持,但很多指令并不支持.默认监听在26379/tcp端口
- 哨兵可以不和Redis服务器部署在一起,但一般部署在一起,所有redis节点使用相同的配置文件
# 如果是编译安装,在源码目录有sentinel.conf,复制到安装目录即可
[root@master ~]# cp redis-5.0.9/sentinel.conf /apps/redis/etc/
[root@master ~]# grep -Ev "^(#|$)" /apps/redis/etc/sentinel.conf
port 26379
daemonize no
pidfile /var/run/redis-sentinel.pid
logfile ""
dir /tmp #工作目录
sentinel monitor mymaster 127.0.0.1 6379 2
#指定当前mymaster集群中master服务器的地址和端口
#2为法定人数限制(quorum),即有几个sentinel认为master down了就进行故障转移,一般此值是所有sentinel节点(一般总数是>=3的 奇数,如:3,5,7等)的一半以上的整数值,比如,总数是3,即3/2=1.5,取整为2,是master的ODOWN客观下线的依据
sentinel auth-pass <master-name> <password>
#mymaster集群中master的密码,注意此行要在上面行的下面
sentinel down-after-milliseconds mymaster 30000
#(SDOWN)判断mymaster集群中所有节点的主观下线的时间,单位:毫秒,建议3000
sentinel parallel-syncs mymaster 1
#发生故障转移后,同时向新master同步数据的slave数量,数字越小总同步时间越长,但可以减轻新master的负载压力
sentinel failover-timeout mymaster 180000
#所有slaves指向新的master所需的超时时间,单位:毫秒
sentinel deny-scripts-reconfig yes
#禁止修改脚本
- 三个哨兵服务器的配置都如下,以master为例
[root@master ~]# grep -Ev "^(#|$)" /apps/redis/etc/sentinel.conf
port 26379
daemonize no
pidfile /apps/redis/run/redis-sentinel.pid
logfile "/apps/redis/log/sentinel.log"
dir /tmp
sentinel monitor mymaster 192.168.88.136 6379 2
sentinel auth-pass mymaster centos
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
[root@master ~]# chown redis.redis /apps/redis/etc/sentinel.conf
启动哨兵
三台哨兵服务器都要启动
# 添加哨兵服务
[root@master ~]# cat << EOF > /lib/systemd/system/redis-sentinel.service
[Unit]
Description=Redis Sentinel
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/apps/redis/bin/redis-sentinel /apps/redis/etc/sentinel.conf --supervised systemd
ExecStop=/usr/libexec/redis-shutdown redis-sentinel
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
[root@master ~]# systemctl daemon-reload
# 确保每个哨兵主机myid不同
#在master上
[root@master ~]# systemctl enable --now redis-sentinel
[root@master ~]# grep myid /apps/redis/etc/sentinel.conf
sentinel myid 4e119d69b1b0bee2a660bcb3162b6116907672e3
# 在slave1上
[root@slave1 ~]# systemctl enable --now redis-sentinel
[root@slave1 ~]# grep myid /apps/redis/etc/sentinel.conf
sentinel myid 946a5a7cb7ab39f46043e2db4f2f41ca1a04ec45
#在slave2上
[root@slave2 ~]# systemctl enable --now redis-sentinel
[root@slave2 ~]# grep myid /apps/redis/etc/sentinel.conf
sentinel myid 8d40b041b85bd197b33a34358169ee7b08de0ecc
# 以下内容在服务启动后自动生成,不需要修改
[root@master ~]# grep mymaster /apps/redis/etc/sentinel.conf
# sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
sentinel monitor mymaster 192.168.175.10 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel auth-pass mymaster centos
# sentinel notification-script mymaster /var/redis/notify.sh
# sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
sentinel config-epoch mymaster 0
# instead of the normal ones. For example if the master "mymaster", and the
# SENTINEL rename-command mymaster CONFIG GUESSME
# SENTINEL rename-command mymaster CONFIG CONFIG
sentinel leader-epoch mymaster 0
sentinel known-replica mymaster 192.168.175.30 6379
sentinel known-replica mymaster 192.168.175.20 6379
sentinel known-sentinel mymaster 192.168.175.30 26379 8d40b041b85bd197b33a34358169ee7b08de0ecc
sentinel known-sentinel mymaster 192.168.175.20 26379 946a5a7cb7ab39f46043e2db4f2f41ca1a04ec45
验证哨兵端口
[root@master ~]# ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 511 *:26379 *:*
查看哨兵日志
[root@master ~]# tail /apps/redis/log/sentinel.log
18077:X 10 Jul 2021 11:23:34.486 # Current maximum open files is 4096. maxclients has been reduced to 4064 to compensate for low ulimit. If you need higher maxclients increase 'ulimit -n'.
18077:X 10 Jul 2021 11:23:34.487 * Running mode=sentinel, port=26379.
18077:X 10 Jul 2021 11:23:34.487 # Sentinel ID is 4e119d69b1b0bee2a660bcb3162b6116907672e3
18077:X 10 Jul 2021 11:23:34.487 # +monitor master mymaster 192.168.175.10 6379 quorum 2
18077:X 10 Jul 2021 11:23:37.553 # +sdown slave 192.168.175.30:6379 192.168.175.30 6379 @ mymaster 192.168.175.10 6379
18077:X 10 Jul 2021 11:23:37.553 # +sdown slave 192.168.175.20:6379 192.168.175.20 6379 @ mymaster 192.168.175.10 6379
18077:X 10 Jul 2021 11:33:18.954 * +sentinel sentinel 946a5a7cb7ab39f46043e2db4f2f41ca1a04ec45 192.168.175.20 26379 @ mymaster 192.168.175.10 6379
18077:X 10 Jul 2021 11:33:22.007 # +sdown sentinel 946a5a7cb7ab39f46043e2db4f2f41ca1a04ec45 192.168.175.20 26379 @ mymaster 192.168.175.10 6379
18077:X 10 Jul 2021 11:33:48.674 * +sentinel sentinel 8d40b041b85bd197b33a34358169ee7b08de0ecc 192.168.175.30 26379 @ mymaster 192.168.175.10 6379
18077:X 10 Jul 2021 11:33:51.763 # +sdown sentinel 8d40b041b85bd197b33a34358169ee7b08de0ecc 192.168.175.30 26379 @ mymaster 192.168.175.10 6379
当前sentinel状态
在sentinel状态中尤其是最后一行,涉及到masterIP是多少,有几个slave,有几个sentinels,必须是符合全部服务器数量
[root@master ~]# redis-cli -p 26379
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.175.10:6379,slaves=2,sentinels=3
停止Redis Master测试故障转移
[root@master ~]# killall redis-server
- 查看各节点上哨兵信息
[root@slave1 ~]# redis-cli -a centos -p 26379
127.0.0.1:26379> INFO sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.175.30:6379,slaves=2,sentinels=3
- 故障转移后的redis配置文件会被自动修改
[root@slave1 ~]# grep "^replicaof" /apps/redis/etc/redis.conf
replicaof 192.168.175.30 6379
- 哨兵配置文件的sentinel monitor IP 同样也会被修改
[root@slave1 ~]# grep monitor /apps/redis/etc/sentinel.conf
sentinel monitor mymaster 192.168.175.30 6379 2
- 新的master 状态
[root@slave2 ~]# redis-cli -a centos --no-auth-warning
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.175.20,port=6379,state=online,offset=289741,lag=1
slave1:ip=192.168.175.10,port=6379,state=online,offset=289741,lag=1
master_replid:de66459a2ecc3f0652fcefc6be633855ccda5c1e
master_replid2:ec21203b0f3034282e18d6532055379b3de45f82
master_repl_offset:289741
second_repl_offset:214083
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:43
repl_backlog_histlen:289699
恢复故障的原master重新加入redis集群
[root@master ~]# systemctl start redis
[root@master ~]#grep "^replicaof" /apps/redis/etc/redis.conf
replicaof 192.168.175.30 6379
[root@master ~]# redis-cli -a centos --no-auth-warning
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.175.30
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:306155
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:de66459a2ecc3f0652fcefc6be633855ccda5c1e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:306155
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:261652
repl_backlog_histlen:44504
sentinel 运维
- 手动让主节点下线
# 指定优先级,值越小sentinel会优先将之选为新的master,默为值为100
[root@master ~]# vim /apps/redis/etc/redis.conf
replica-priority 10
[root@master ~]# systemctl restart redis
[root@master ~]# redis-cli -a centos -p 26379
127.0.0.1:26379> sentinel failover mymaster
OK
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.175.10:6379,slaves=2,sentinels=3
python连接redis
- 客户端链接sentinel工作原理
- 选举出一个sentinel
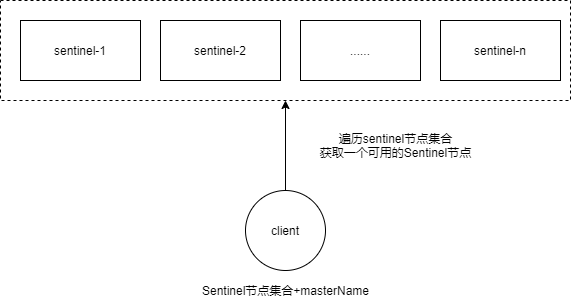
- 由这个sentinel 通过masterName 获取master节点信息
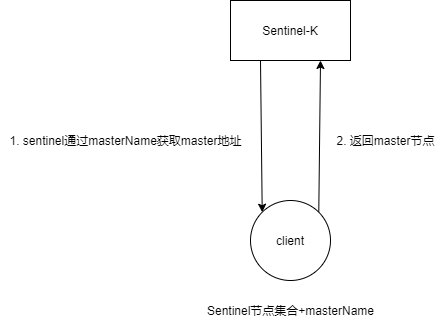
- sentinel 发送role指令确认mater的信息
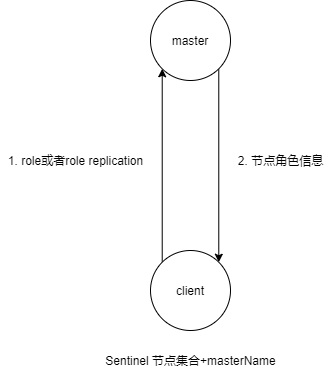
- 客户端订阅sentinel的相关频道,获取新的master 信息变化,并自动连接新的master
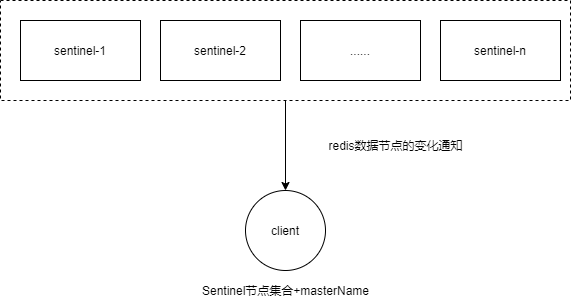
python 连接Sentinel哨兵
[root@master ~]# yum -y install python3 python3-redis
[root@master ~]# vim sentinel_test.py
#!/usr/bin/python3
import redis
from redis.sentinel import Sentinel
#连接哨兵服务器(主机名也可以用域名)
sentinel = Sentinel([('192.168.175.10', 26379),
('192.168.175.20', 26379),
('192.168.175.30', 26379)],
socket_timeout=0.5)
redis_auth_pass = 'centos'
#mymaster 是配置哨兵模式的redis集群名称,此为默认值,实际名称按照个人部署案例来填写
#获取主服务器地址
master = sentinel.discover_master('mymaster')
print(master)
#获取从服务器地址
slave = sentinel.discover_slaves('mymaster')
print(slave)
#获取主服务器进行写入
master = sentinel.master_for('mymaster', socket_timeout=0.5,
password=redis_auth_pass, db=0)
w_ret = master.set('name', 'eagle')
#输出:True
#获取从服务器进行读取(默认是round-roubin)
slave = sentinel.slave_for('mymaster', socket_timeout=0.5,
password=redis_auth_pass, db=0)
r_ret = slave.get('name')
print(r_ret)
#输出:eagle
[root@master ~]# python3 sentinel_test.py
('192.168.175.10', 6379)
[('192.168.175.20', 6379), ('192.168.175.30', 6379)]
b'eagle'
Redis Cluster

Redis Cluster 工作原理
在哨兵sentinel机制中,可以解决redis高可用问题,即当master故障后可以自动将slave提升为master,从而可以保证redis服务的正常使用,但是无法解决redis单机写入的瓶颈问题,即单机redis写入性能受限于单机的内存大小、并发数量、网卡速率等因素。
- 早期Redis 分布式集群部署方案
- 客户端分区:由客户端程序决定key写分配和写入的redis node,但是需要客户端自己处理写入分配、高可用管理和故障转移等
- 代理方案:基于三方软件实现redis proxy,客户端先连接至代理层,由代理层实现key的写入分配,对客户端来说是有比较简单,但是对于集群管理节点增减相对比较麻烦,而且代理本身也是单点和性能瓶颈。
redis 3.0版本之后推出了无中心架构的redis cluster机制,在无中心的redis集群当中,其每个节点保存当前节点数据和整个集群状态,每个节点都和其他所有节点连接
- Redis Cluster特点如下
- 所有Redis节点使用(PING机制)互联
- 集群中某个节点的是否失效,是由整个集群中超过半数的节点监测都失效,才能算真正的失效
- 客户端不需要proxy即可直接连接redis,应用程序中需要配置有全部的redis服务器IP
- redis cluster把所有的redis node 平均映射到 0-16383个槽位(slot)上,读写需要到指定的redis node上进行操作,因此有多少个redis node相当于redis 并发扩展了多少倍,每个redis node 承担16384/N个槽位
- Redis cluster预先分配16384个(slot)槽位,当需要在redis集群中写入一个key -value的时候,会使用CRC16(key) mod 16384之后的值,决定将key写入值哪一个槽位从而决定写入哪一个Redis节点上,从而有效解决单机瓶颈。
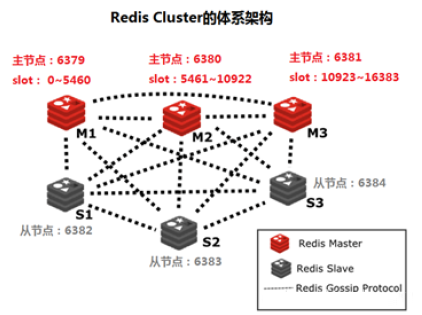
Redis cluster 基本架构
假如三个主节点分别是:A,B,C三个节点,采用哈希槽(hash slot)的方式来分配16384个slot的活,它们三个节点分别承担的slot 区间可以是:
- 节点A覆盖:0-5460
- 节点B覆盖:5461-10922
- 节点C覆盖:10923-16383
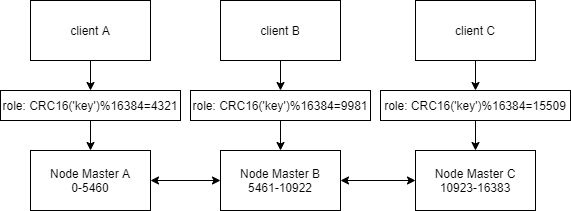
Redis cluster 主从架构
Redis cluster的架构虽然解决了并发的问题,但是又引入了一个新的问题,每个Redis master的高可用如何解决?
那就是对每个master 节点都实现主从复制,从而实现 redis 高可用性
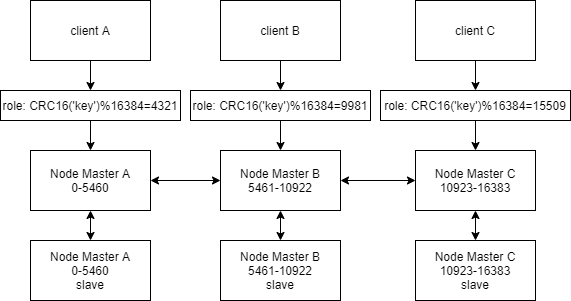
Redis Cluster 部署架构说明
- 环境A:3台服务器,每台服务器启动6379和6380两个redis 服务实例,适用于测试环境
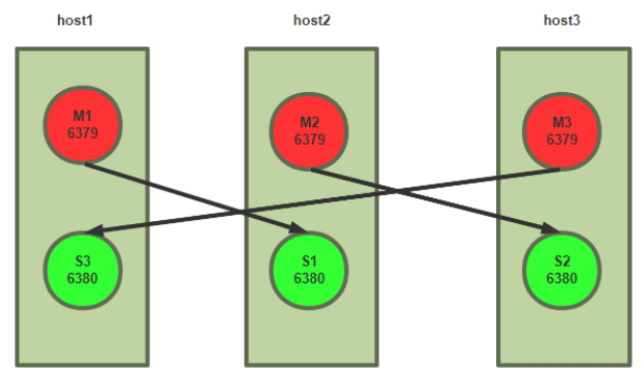
- 环境B:6台服务器,分别是三组master/slave,适用于生产环境
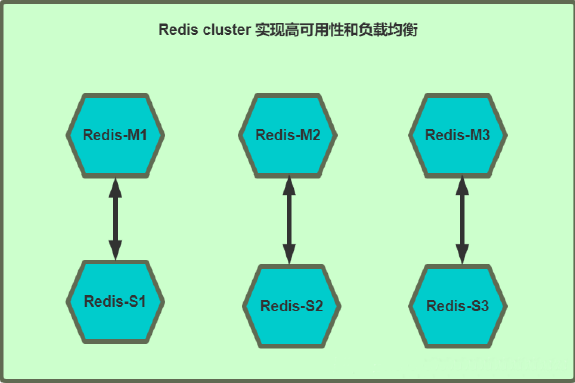
部署方式介绍
- redis cluster 有多种部署方法
- 原生命令安装
- 理解Redis Cluster架构
- 生产环境不使用
- 官方工具安装
- 高效、准确
- 生产环境可以使用
- 自主研发
- 可以实现可视化的自动化部署
原生命令手动部署
- 在所有节点安装redis,并配置开启cluster功能
- 各个节点执行meet,实现所有节点的相互通信
- 为各个master 节点指派槽位范围
- 指定各个节点的主从关系
原生命令
- 集群
- cluster info :打印集群的信息
- cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
- 节点
- cluster meet :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
- cluster forget
:从集群中移除 node_id 指定的节点。 - cluster replicate
:将当前从节点设置为 node_id 指定的master节点的slave节点。只能针对slave节点操作。 - cluster saveconfig :将节点的配置文件保存到硬盘里面。
- 槽(slot)
- cluster addslots [slot ...] :将一个或多个槽( slot)指派( assign)给当前节点。
- cluster delslots [slot ...] :移除一个或多个槽对当前节点的指派。
- cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
- cluster setslot node
:将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给 - 另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
- cluster setslot migrating
:将本节点的槽 slot 迁移到 node_id 指定的节点中。 - cluster setslot importing
:从 node_id 指定的节点中导入槽 slot 到本节点。 - cluster setslot stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
- 键
- cluster keyslot :计算键 key 应该被放置在哪个槽上。
- cluster countkeysinslot :返回槽 slot 目前包含的键值对数量。
- cluster getkeysinslot :返回 count 个 slot 槽中的键 。
实战案例: 利用原生命令手动部署redis cluster
- 准备6台虚拟机
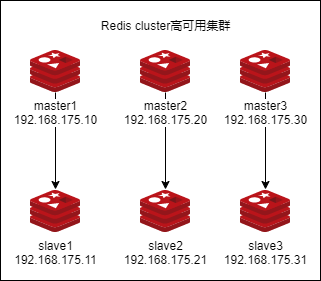
- 在所有节点安装redis并启动cluster功能
#在克隆之前将如下操作在模板上操作完成
[root@localhost ~]# vim redis_install.sh
#参照一键编译安装redis脚本
[root@localhost ~]# . redis_install.sh
# 开始编译安装redis
- 将克隆过的主机的IP地址配置完成,防火墙放行对应的端口号
firewall-cmd --add-port=1-65535/tcp --permanent
firewall-cmd --add-port=1-65535/udp --permanent
firewall-cmd --reload
hostnamectl set-hostname master1
- 启用redis集群支持
[root@master1 ~]# vim /apps/redis/etc/redis.conf
cluster-enabled yes
[root@master1 ~]# systemctl restart redis
- 执行 meet 操作实现相互通信
# 在任意一节点上和其它所有节点进行meet通信,以master1为例
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster meet 192.168.175.11 6379
OK
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster meet 192.168.175.20 6379
OK
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster meet 192.168.175.21 6379
OK
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster meet 192.168.175.30 6379
OK
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster meet 192.168.175.31 6379
OK
#可以看到所有节点之间可以相互连接通信,以master1为例
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster nodes
76da144ef9ea65664f9ba5ac431ed9e26b07b132 192.168.175.31:6379@16379 master - 0 1625909926530 4 connected
fae9fe337678873ec0f3e0a44c39bd8064c85fb0 192.168.175.30:6379@16379 master - 0 1625909925000 0 connected
5eeb5ce103710ec5108d3257fdcd019b401548d9 192.168.175.11:6379@16379 master - 0 1625909926000 3 connected
3ccb32a3e79572a16a1aa3e8188fff07121b1d1e 192.168.175.20:6379@16379 master - 0 1625909927549 2 connected
48000fa51e653b3dbf3f70829fc9142c40195ff6 192.168.175.10:6379@16379 myself,master - 0 1625909927000 1 connected
e1b815df722f7c202e28215fa23ff20913d88479 192.168.175.21:6379@16379 master - 0 1625909924486 5 connected
- 由于没有分配槽位,无法创建key
[root@master1 ~]# redis-cli -a centos --no-auth-warning set name eagle
(error) CLUSTERDOWN Hash slot not served
- 查看当前状态,以master1为例
[root@master1 ~]# redis-cli -a centos --no-auth-warning cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:289
cluster_stats_messages_pong_sent:290
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:584
cluster_stats_messages_ping_received:289
cluster_stats_messages_pong_received:294
cluster_stats_messages_meet_received:1
cluster_stats_messages_received:584
- 为每个master 节点指派槽位范围
[root@master1 ~]# vim addslots.sh
#!/bin/bash
HOST=$1
PORT=$2
START=$3
END=$4
PASS=centos
for slot in `seq ${START} ${END}`;do
echo "slot: ${slot}"
redis-cli -h ${HOST} -p ${PORT} -a ${PASS} --no-auth-warning cluster addslots ${slot}
done
* 为三个master分配槽位,共16364/3=5461.33333,平均每个master分配5461个槽位
[root@master1 ~]# bash addslots.sh 192.168.175.10 6379 0 5461
#当master1分配完槽位后,可以看到下面信息
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster info
cluster_state:fail
cluster_slots_assigned:5462
cluster_slots_ok:5462
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:1
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:504
cluster_stats_messages_pong_sent:500
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:1009
cluster_stats_messages_ping_received:499
cluster_stats_messages_pong_received:509
cluster_stats_messages_meet_received:1
cluster_stats_messages_received:1009
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster nodes
76da144ef9ea65664f9ba5ac431ed9e26b07b132 192.168.175.31:6379@16379 master - 0 1625910366128 4 connected
fae9fe337678873ec0f3e0a44c39bd8064c85fb0 192.168.175.30:6379@16379 master - 0 1625910366000 0 connected
5eeb5ce103710ec5108d3257fdcd019b401548d9 192.168.175.11:6379@16379 master - 0 1625910365000 3 connected
3ccb32a3e79572a16a1aa3e8188fff07121b1d1e 192.168.175.20:6379@16379 master - 0 1625910367145 2 connected
48000fa51e653b3dbf3f70829fc9142c40195ff6 192.168.175.10:6379@16379 myself,master - 0 1625910366000 1 connected 0-5461
e1b815df722f7c202e28215fa23ff20913d88479 192.168.175.21:6379@16379 master - 0 1625910368168 5 connected
# 当所有的三个master分配完槽位后,可以看到如下信息,以master1为例,在其它主机看到的信息一样
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster nodes
76da144ef9ea65664f9ba5ac431ed9e26b07b132 192.168.175.31:6379@16379 master - 0 1625912355000 4 connected
3ccb32a3e79572a16a1aa3e8188fff07121b1d1e 192.168.175.20:6379@16379 master - 0 1625912353000 2 connected 5462-10922
fae9fe337678873ec0f3e0a44c39bd8064c85fb0 192.168.175.30:6379@16379 master - 0 1625912355795 0 connected 10923-16383
5eeb5ce103710ec5108d3257fdcd019b401548d9 192.168.175.11:6379@16379 master - 0 1625912354000 3 connected
48000fa51e653b3dbf3f70829fc9142c40195ff6 192.168.175.10:6379@16379 myself,master - 0 1625912351000 1 connected 0-5461
e1b815df722f7c202e28215fa23ff20913d88479 192.168.175.21:6379@16379 master - 0 1625912354000 5 connected
- 指定各个节点的主从关系
# 通过上面的cluster nodes 查看master的ID信息,执行下面操作,将对应的slave 指定相应的master节点,实现三对主从节点
[root@master1 ~]# redis-cli -h 192.168.175.11 -a centos --no-auth-warning cluster replicate 48000fa51e653b3dbf3f70829fc9142c40195ff6
OK
[root@master1 ~]# redis-cli -h 192.168.175.21 -a centos --no-auth-warning cluster replicate 3ccb32a3e79572a16a1aa3e8188fff07121b1d1e
OK
[root@master1 ~]# redis-cli -h 192.168.175.31 -a centos --no-auth-warning cluster replicate fae9fe337678873ec0f3e0a44c39bd8064c85fb0
OK
- 查看主从节点关系及槽位信息
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning cluster slots
1) 1) (integer) 5462
2) (integer) 10922
3) 1) "192.168.175.20"
2) (integer) 6379
3) "3ccb32a3e79572a16a1aa3e8188fff07121b1d1e"
4) 1) "192.168.175.21"
2) (integer) 6379
3) "e1b815df722f7c202e28215fa23ff20913d88479"
2) 1) (integer) 10923
2) (integer) 16383
3) 1) "192.168.175.30"
2) (integer) 6379
3) "fae9fe337678873ec0f3e0a44c39bd8064c85fb0"
4) 1) "192.168.175.31"
2) (integer) 6379
3) "76da144ef9ea65664f9ba5ac431ed9e26b07b132"
3) 1) (integer) 0
2) (integer) 5461
3) 1) "192.168.175.10"
2) (integer) 6379
3) "48000fa51e653b3dbf3f70829fc9142c40195ff6"
4) 1) "192.168.175.11"
2) (integer) 6379
3) "5eeb5ce103710ec5108d3257fdcd019b401548d9"
- 验证 redis cluster 访问
- -c 表示以集群方式连接
[root@master1 ~]# redis-cli -c -h 192.168.175.10 -a centos --no-auth-warning set name eagle
OK
[root@master1 ~]# redis-cli -c -h 192.168.175.10 -a centos --no-auth-warning get name
"eagle"
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning get name
(error) MOVED 5798 192.168.175.20:6379
[root@master1 ~]# redis-cli -h 192.168.175.20 -a centos --no-auth-warning get name
"eagle"
[root@master1 ~]# redis-cli -h 192.168.175.30 -a centos --no-auth-warning get name
(error) MOVED 5798 192.168.175.20:6379
实战案例:基于Redis 5 的 redis cluster 部署
官方文档:https://redis.io/topics/cluster-tutorial
# cluste选项帮助
[root@master1 ~]# redis-cli --cluster help
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN #创建集群
--replicas <arg> #指定master的副本数量
check host:port #检查集群信息
info host:port #查看集群主机信息
fix host:port #修复集群
--timeout <arg>
reshard host:port #在线热迁移集群指定主机的slots数据
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
rebalance host:port #平衡集群中各主机的slot数量
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
add-node new_host:new_port existing_host:existing_port #添加主机到集群
--slave
--master-id <arg>
del-node host:port node_id #删除主机
set-timeout host:port milliseconds #设置节点的超时时间
call host:port command arg arg .. arg #在集群上的所有节点上执行命令
import host:port #导入外部redis服务器的数据到当前集群
--from <arg>
--copy
--replace
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
- 创建 redis cluster集群的环境准备
- 每个redis 节点采用相同的硬件配置、相同的密码、相同的redis版本
- 所有redis服务器必须没有任何数据
- 准备6台主机,开启cluster配置
创建集群
# redis-cli --cluster-replicas 1 表示每个master对应一个slave节点
[root@master1 ~]# redis-cli -a centos --no-auth-warning --cluster create \
192.168.175.10:6379 192.168.175.20:6379 192.168.175.30:6379 \
192.168.175.11:6379 192.168.175.21:6379 192.168.175.31:6379 \
--cluster-replicas 1
# 观察运行结果,可以看到3组master/slave
查看主从状态
[root@master1 ~]# redis-cli -c -h 192.168.175.10 -a centos info replication
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Replication
role:master
connected_slaves:0
master_replid:19f199fca5cf6fcd15aa6db3d7482c302923f84d
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
[root@master1 ~]# redis-cli -c -h 192.168.175.11 -a centos info replication
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Replication
role:slave
master_host:192.168.175.30
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:1
master_link_down_since_seconds:1625915270
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:d322eda9ed8308deae297ad5920a22e43a1d24ab
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
- 查看指定master节点的slave节点信息
[root@master1 ~]# redis-cli -a centos cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
449ef170cd83b0d42c47e6504210699770b7a9fa 192.168.175.30:6379@16379 master - 0 1625915361650 3 connected 10923-16383
1329d448ec1f4abcf39ba03cdeed484c869a27b5 192.168.175.10:6379@16379 myself,master - 0 1625915359000 1 connected 0-5460
464d5cbe572a69ae6c95c82f2ce5942dbc8a848a 192.168.175.31:6379@16379 slave f8f0d5dec65001f4082c6db805fff98777636e00 0 1625915361000 6 connected
09f2f31bf45b91a04bab1e798a3f053104edfcd5 192.168.175.21:6379@16379 slave 1329d448ec1f4abcf39ba03cdeed484c869a27b5 0 1625915362668 5 connected
74a4f661379361a38f4bef603bc1807025527b4b 192.168.175.11:6379@16379 slave 449ef170cd83b0d42c47e6504210699770b7a9fa 0 1625915361000 4 connected
f8f0d5dec65001f4082c6db805fff98777636e00 192.168.175.20:6379@16379 master - 0 1625915362000 2 connected 5461-10922
验证集群状态
[root@master1 ~]# redis-cli -a centos --no-auth-warning cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6 #节点数
cluster_size:3 #3个集群
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:342
cluster_stats_messages_pong_sent:362
cluster_stats_messages_sent:704
cluster_stats_messages_ping_received:357
cluster_stats_messages_pong_received:342
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:704
查看集群node对应关系
[root@master1 ~]# redis-cli -a centos --no-auth-warning cluster nodes
449ef170cd83b0d42c47e6504210699770b7a9fa 192.168.175.30:6379@16379 master - 0 1625915444000 3 connected 10923-16383
1329d448ec1f4abcf39ba03cdeed484c869a27b5 192.168.175.10:6379@16379 myself,master - 0 1625915446000 1 connected 0-5460
464d5cbe572a69ae6c95c82f2ce5942dbc8a848a 192.168.175.31:6379@16379 slave f8f0d5dec65001f4082c6db805fff98777636e00 0 1625915446000 6 connected
09f2f31bf45b91a04bab1e798a3f053104edfcd5 192.168.175.21:6379@16379 slave 1329d448ec1f4abcf39ba03cdeed484c869a27b5 0 1625915447384 5 connected
74a4f661379361a38f4bef603bc1807025527b4b 192.168.175.11:6379@16379 slave 449ef170cd83b0d42c47e6504210699770b7a9fa 0 1625915443298 4 connected
f8f0d5dec65001f4082c6db805fff98777636e00 192.168.175.20:6379@16379 master - 0 1625915447000 2 connected 5461-10922
验证集群写入key
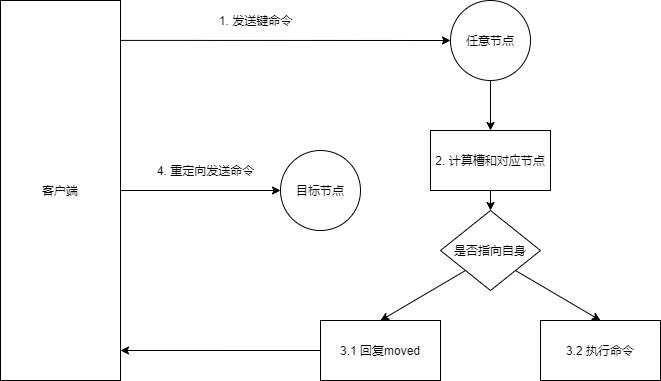
- redis cluster 写入key
[root@master1 ~]# redis-cli -h 192.168.175.10 -a centos --no-auth-warning set name eagle
(error) MOVED 5798 192.168.175.20:6379 #槽位不在当前node所以无法写入
[root@master1 ~]# redis-cli -h 192.168.175.20 -a centos --no-auth-warning set name eagle
OK
[root@master1 ~]# redis-cli -h 192.168.175.20 -a centos --no-auth-warning get name
"eagle"
模拟master故障
- 对应的slave节点自动提升为新master
- 模拟master3节点出故障,需要相应的数秒故障转移时间
[root@master3 ~]# redis-cli -a centos --no-auth-warning
127.0.0.1:6379> shutdown
not connected> exit
[root@master3 ~]# redis-cli -a centos --no-auth-warning --cluster info 192.168.175.10:6379
Could not connect to Redis at 192.168.175.30:6379: Connection refused
192.168.175.10:6379 (c5fd0661...) -> 3333 keys | 5461 slots | 1 slaves.
192.168.175.20:6379 (1cd30e11...) -> 3341 keys | 5462 slots | 1 slaves.
192.168.175.31:6379 (4e42a7da...) -> 3330 keys | 5461 slots | 0 slaves. #192.168.175.31为新的master
[OK] 10004 keys in 3 masters.
0.61 keys per slot on average.