通配符
Linux 中的通配符是一种特殊的符号,用于匹配文件名或目录名。这些通配符可以帮助用户更快地输入命令和文件路径。或者可以理解为用户文件名和路径的匹配。由shell进行解析,一般情况下与某些命令配合使用,如:find,cp,mv,ls,rm等。
Shell中常见的通配符如下:
*: 匹配0或多个字符
?: 匹配任意一个字符
[....]: 匹配方括号中任意单个字符
[!....]: 匹配除了方括号中指定字符之外的字符
范围 [a-z]: 匹配指定范围内的任意一个字符
大括号 {}: 用于匹配由逗号分隔的单个字符串
Shell元字符
在 Shell 脚本中,除了通配符,还有一些特殊的元字符需要了解。这些元字符有特殊的含义,在编写 Shell 脚本时需要特别注意。以下是 Shell 中常见的一些元字符及其用法
IFS:<tab>/<space>/<enter>
=:设定变量
$:取变量值
>/< :重定向
|:管道
&:后台执行命令
():在子shell中执行命令/运算或命令替换
{}:用于扩展变量、生成序列等。
例如 echo {A..Z} 会输出 A 到 Z 的大写字母序列。
;:命令结束后,忽略其返回值,继续执行下一个命令
&&:命令结束后,若为true,继续执行下一个命令
||:命令结束后,若为false,继续执行下一个命令
!:非
#:注释
\:转义符
Shell中的转义符:
1. 反斜杠 \: 是最常用的转义符,用于转义其后的一个字符
例如 echo "This is a backslash: \\" 会输出 This is a backslash: \
2. 单引号'...': 可以将整个字符串括起来,使其中的特殊字符失去特殊含义,硬转义
3. 双引号"...": 内部的大部分特殊字符仍然保留特殊含义,软转义
示例:
echo 'Hello, $USER' 输出---> Hello, $USER
echo "Hello, $USER" 输出---> Hello, root
find文件查找
实时查找工具,通过遍历指定路径下的文件系统完成文件查找
工作特点:
- 查找速度略慢
- 精确查找
- 实时查找
- 可以满足多种条件匹配
find [选项] [路径] [查找条件 + 处理动作]
查找路径:指定具体目录路径,默认是当前文件夹
查找条件:指定的查找标准(文件名/大小/类型/权限等),默认是找出所有文件
处理动作:对符合条件的文件做什么操作,默认输出屏幕
查找条件
根据文件名查找:
‐name "filename" 支持global
‐iname "filename" 忽略大小写
‐regex "PATTERN" 以Pattern匹配整个文件路径字符串,而不仅仅是文件名称
根据属主和属组查找:
‐user USERNAME:查找属主为指定用户的文件
‐group GROUPNAME:查找属组为指定属组的文件
‐uid UserID:查找属主为指定的ID号的文件
‐gid GroupID:查找属组为指定的GID号的文件
‐nouser:查找没有属主的文件
‐nogroup:查找没有属组的文件
根据文件类型查找:
‐type Type:
f/d/l/s/b/c/p
根据文件大小来查找:
‐size [+|‐]N[bcwkMG]
根据时间戳:
天:
‐atime [+|‐]N
‐mtime
‐ctime
分钟:
‐amin N
‐cmin N
‐mmin N
根据权限查找:
‐perm [+|‐]MODE
MODE:精确权限匹配
/MODE:任何一类(u,g,o)对象的权限中只要能一位匹配即可
‐MODE:每一类对象都必须同时拥有为其指定的权限标准
组合条件:
与:‐a 多个条件and并列
或:‐o 多个条件or并列
非:‐not 条件取反
示例:
- 根据文件名查找
[root@localhost ~]# find /etc -name "ifcfg-ens33"
[root@localhost ~]# find /etc -iname "ifcfg-ens33" # 忽略大小写
[root@localhost ~]# find /etc -iname "ifcfg*"
- 按文件大小
[root@localhost ~]# find /etc -size +5M # 大于5M
[root@localhost ~]# find /etc -size 5M # 等于5M
[root@localhost ~]# find /etc -size -5M # 小于5M
[root@localhost ~]# find /etc -size +5M -ls # 找到的处理动作-ls
- 指定查找的目录深度
[root@localhost ~]# find / -maxdepth 3 -a -name "ifcfg-ens33" # 最大查找深度
# -a是同时满足,-o是或
[root@localhost ~]# find / -mindepth 3 -a -name "ifcfg-ens33" # 最小查找深度
- 按时间找
[root@localhost ~]# find /etc -mtime +5 # 修改时间超过5天
[root@localhost ~]# find /etc -mtime 5 # 修改时间等于5天
[root@localhost ~]# find /etc -mtime -5 # 修改时间5天以内
- 按照文件属主、属组找,文件的属主和属组,会在下一篇详细讲解。
[root@localhost ~]# find /home -user xwz # 属主是xwz的文件
[root@localhost ~]# find /home -group xwz
[root@localhost ~]# find /home -user xwz -group xwz
[root@localhost ~]# find /home -user xwz -a -group root
[root@localhost ~]# find /home -user xwz -o -group root
[root@localhost ~]# find /home -nouser # 没有属主的文件
[root@localhost ~]# find /home -nogroup # 没有属组的文件
- 按文件类型
[root@localhost ~]# find /dev -type d
- 按文件权限
[root@localhost ~]# find / -perm 644 -ls
[root@localhost ~]# find / -perm -644 -ls # 权限小于644的
[root@localhost ~]# find / -perm 4000 -ls
[root@localhost ~]# find / -perm -4000 -ls
- 按正则表达式
[root@localhost ~]# find /etc -regex '.*ifcfg-ens[0-9][0-9]'
# .* 任意多个字符
# [0-9] 任意一个数字
处理动作
‐print:默认的处理动作,显示至屏幕
‐ls:类型于对查找到的文件执行“ls ‐l”命令
‐delete:删除查找到的文件
‐fls /path/to/somefile:查找到的所有文件的长格式信息保存至指定文件中
‐ok COMMAND {}\:对查找到的每个文件执行由COMMAND指定的命令
并且对于每个文件执行命令之前,都会交换式要求用户确认
‐exec COMMAND {} \:对查找到的每个文件执行由COMMAND指定的命令
{}:用于引用查找到的文件名称自身
[root@server1 ~]# find /etc/init.d/ -perm -111 -exec cp -r {} dir1/ \;
正则表达式
正则表达式是一种强大的文本匹配和处理工具。它允许你定义复杂的匹配模式,在文本中查找、替换和操作数据。正则表达式被广泛应用于各种文本处理工具和命令中,如 sed、awk、grep 等.....
1. 字符匹配
- `.`:匹配任意单个字符
- `[]`:匹配指定范围内任意单个字符 `[a-z]` `[0-9]`
- `[^]`:匹配指定范围外任意单个字符 `[^a-z]` `[^0-9]`
- `[:alnum:]`:字母与数字字符
- `[:alpha:]`:字母
- `[:ascii:]`:ASCII 字符
- `[:blank:]`:空格或制表符
- `[:cntrl:]`:ASCII 控制字符
- `[:digit:]`:数字
- `[:graph:]`:非控制、非空格字符
- `[:lower:]`:小写字母
- `[:print:]`:可打印字符
- `[:punct:]`:标点符号字符
- `[:space:]`:空白字符,包括垂直制表符
- `[:upper:]`:大写字母
- `[:xdigit:]`:十六进制数字
2. 匹配次数
- `*`:匹配前面的字符任意次数
- `.*`:匹配任意长度的字符
- `\?`:匹配其前面字符 0 或 1 次,即前面的可有可无 `'a\?b'`
- `\+`:匹配其前面的字符至少 1 次 `'a\+b'`
- `\{m\}`:匹配前面的字符 m 次
- `\{m,n\}`:匹配前面的字符至少 m 次,至多 n 次
- `\{0,n\}`:匹配前面的字符至多 n 次
- `\{m,\}`:匹配前面的字符至少 m 次
3. 位置锚定
- `^`:行首锚定,用于模式的最左侧
- `$`:行末锚定,用于模式的最右侧
- `^PATTERN$`:用于模式匹配整行
- `^$`:空行
- `\<` 或 `\b`:词首锚定,用于单词模式的左侧
- `\>` 或 `\b`:词尾锚定,用于单词模式的右侧
- `\<PATTERN\>`:匹配整个单词 `'\<hello\>'`
4. 分组
- `()`: 用于分组,可以对一组字符应用量词等操作
- 分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中
- `\1`、`\2` 等: 用于引用前面匹配的分组内容
- `\1`:从左侧起,第一个左括号以及与之匹配右括号之间的模式所匹配到的字符;
文本三剑客之grep
grep作用:过滤文本内容
| 选项 | 描述 |
|---|---|
| -E :--extended--regexp | 模式是扩展正则表达式(ERE) |
| -i :--ignore--case | 忽略大小写 |
| -n: --line--number | 打印行号 |
| -o:--only--matching | 只打印匹配的内容 |
| -c:--count | 只打印每个文件匹配的行数 |
| -B:--before--context=NUM | 打印匹配的前几行 |
| -A:--after--context=NUM | 打印匹配的后几行 |
| -C:--context=NUM | 打印匹配的前后几行 |
| --color[=WHEN] | 匹配的字体颜色,别名已定义了 |
| -v:--invert--match | 打印不匹配的行 |
| -e | 多点操作eg:grep -e "^s" -e "s$" |
案例
文本内容:
[root@localhost ~]# python -c "import this" > file
[root@localhost ~]# cat file
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
案例1:过滤出所有包含a的行,无论大小写
[root@localhost ~]# grep -i "a" file
[root@localhost ~]# grep "a" file
结果.....
案例2:过滤出所有包含a的行,无论大小写,并且显示该行所在的行号
[root@localhost ~]# grep -in "a" file
3:Beautiful is better than ugly.
4:Explicit is better than implicit.
5:Simple is better than complex.
6:Complex is better than complicated.
7:Flat is better than nested.
8:Sparse is better than dense.
9:Readability counts.
10:Special cases aren't special enough to break the rules.
11:Although practicality beats purity.
12:Errors should never pass silently.
14:In the face of ambiguity, refuse the temptation to guess.
15:There should be one-- and preferably only one --obvious way to do it.
16:Although that way may not be obvious at first unless you're Dutch.
17:Now is better than never.
18:Although never is often better than *right* now.
19:If the implementation is hard to explain, it's a bad idea.
20:If the implementation is easy to explain, it may be a good idea.
21:Namespaces are one honking great idea -- let's do more of those!
案例3:仅仅打印出所有匹配的字符或者字符串
[root@localhost ~]# grep -o "a" file
结果....
案例4:统计匹配到的字符或字符串总共的行数
[root@localhost ~]# grep -c "a" file
18
案例5:打印所匹配到的字符串的前几行
[root@localhost ~]# grep -B 2 "Simple" file
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
案例6:打印所匹配到的字符串的后几行
[root@localhost ~]# grep -A 3 "Simple" file
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
案例7:打印所匹配到的字符串的前后几行
[root@localhost ~]# grep -C 1 "Simple" file
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
案例8:取反,过滤出不包含Simple的行
[root@localhost ~]# grep -vn "Simple" file
1:The Zen of Python, by Tim Peters
2:
3:Beautiful is better than ugly.
4:Explicit is better than implicit.
6:Complex is better than complicated.
7:Flat is better than nested.
8:Sparse is better than dense.
9:Readability counts.
10:Special cases aren't special enough to break the rules.
11:Although practicality beats purity.
12:Errors should never pass silently.
13:Unless explicitly silenced.
14:In the face of ambiguity, refuse the temptation to guess.
15:There should be one-- and preferably only one --obvious way to do it.
16:Although that way may not be obvious at first unless you're Dutch.
17:Now is better than never.
18:Although never is often better than *right* now.
19:If the implementation is hard to explain, it's a bad idea.
20:If the implementation is easy to explain, it may be a good idea.
21:Namespaces are one honking great idea -- let's do more of those!
正则表达式(基于grep)
- 功能就是用来检索、替换那些符合某个模式(规则)的文本,正则表达式在每种语言中都会有;
- 正则表达式就是为了处理大量的文本或字符串而定义的一套规则和方法
- 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串
- Linux正则表达式一般以行为单位处理
基础正则表达式
| 符号 | 描述 |
|---|---|
| . | 匹配任意单个字符(必须存在) |
| ^ | 匹配以某个字符开头的行 |
| $ | 配以什么字符结尾的行 |
| * | 匹配前面的一个字符出现0次或者多次;eg:a*b |
| .* | 表示任意长度的任意字符 |
| [] | 表示匹配括号内的一个字符 |
| [^] | 匹配[^字符]之外的任意一个字符 |
| [] | 匹配非[^字符]内字符开头的行 |
| < | 锚定 单词首部;eg:\<root |
| > | 锚定 单词尾部:eg:root\> |
| {m,n} | 表示匹配前面的字符出现至少m次,至多n次 |
| () | 表示对某个单词进行分组;\1表示第一个分组进行调用 |
扩展正则
- egrep ...
grep -E ...
扩展正则支持所有基础正则;并有补充
- 扩展正则中{}和[]不用转义可以直接使用;
| 符号 | 描述 | |
|---|---|---|
| + | 表示前面的字符至少出现1次的情况 | |
| \ | 表示“或” | |
| ? | 表示前面的字符至多出现1次的情况 |
最常用:查看配置文件时去除所有的注释和空行
[root@localhost ~]# grep -Ev "^#|^$" /etc/ssh/sshd_config
获取IP地址:
[root@localhost ~]# ifconfig ens33 | grep inet | grep -E '\.' | grep -oE '([[:digit:]]{1,3}\.){3}[[:digit:]]{1,3}' | head -n 1
192.168.88.10
文本三剑客之sed
(文本处理工具)
sed 是一个强大的文本处理工具,它可以用于对文本进行搜索、替换、删除、插入等操作。
sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
语法
sed的命令格式: sed [option] 'sed command' filename
sed的脚本格式:sed [option] ‐f 'sed script' filename
常用选项:
‐n :只打印模式匹配的行
‐e :直接在命令行模式上进行sed动作编辑,此为默认选项
‐f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作
‐r :支持扩展表达式
‐i :直接修改文件内容
查询文本的方式
使用行号和行号范围
x:行号
x,y:从x行到y行
x,y!:x行到y行之外
/pattern:查询包含模式的行
/pattern/, /pattern/:查询包含两个模式的行
/pattern/,x:x行内查询包含模式的行
x,/pattern/:x行后查询匹配模式的行
动作说明
常用选项:
p:打印匹配的行(‐n)
=:显示文件行号
a\:指定行号后添加新文本
i\:指定行号前添加新文本
d:删除定位行
c\:用新文本替换定位文本
w filename:写文本到一个文件
r filename:从另一个文件读文本
s///:替换
替换标记:
g:行内全局替换
p:显示替换成功的行
w:将替换成功的结果保存至指定文件
q:第一个模式匹配后立即退出
{}:在定位行执行的命令组,用逗号分隔
g:将模式2粘贴到/pattern n/
案例
在testfile文件的第四行后添加一行,并将结果输出到标准输出
[root@localhost ~]# vim testfile
[root@localhost ~]# sed -e 4a\newline testfile
line one
line two
line three
line four
newline
line five
以行为单位的新增/删除
- 将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除
[root@localhost ~]# nl /etc/passwd | sed '2,5d'
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
- 只删除第2行
[root@localhost ~]# nl /etc/passwd | sed '2d'
1 root:x:0:0:root:/root:/bin/bash
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
- 删除第3行到最后一行的内容
[root@localhost ~]# nl /etc/passwd | sed '3,$d'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
- 在第2行后面新增helloworld字符
[root@localhost ~]# nl /etc/passwd | sed '2a\hello world'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
hello world
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
- 加到第2行的前面
[root@localhost ~]# nl /etc/passwd | sed '2i\hello world'
1 root:x:0:0:root:/root:/bin/bash
hello world
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
- 添加多行内容
[root@localhost ~]# nl /etc/passwd | sed "2a\hello world\nnihao"
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
hello world
nihao
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
以行为单位的替换与显示
- 将第2-5行的内容取代为”No 2-5 number“
[root@localhost ~]# nl /etc/passwd | sed '2,5c\No 2-5 number'
1 root:x:0:0:root:/root:/bin/bash
No 2-5 number
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
- 修改SElinux的模式
[root@localhost ~]# nl /etc/selinux/config | sed '7c\SELINUX=permissive'
1 # This file controls the state of SELinux on the system.
2 # SELINUX= can take one of these three values:
3 # enforcing - SELinux security policy is enforced.
4 # permissive - SELinux prints warnings instead of enforcing.
5 # disabled - No SELinux policy is loaded.
SELINUX=permissive
7 # SELINUXTYPE= can take one of three values:
8 # targeted - Targeted processes are protected,
9 # minimum - Modification of targeted policy. Only selected processes are protected.
10 # mls - Multi Level Security protection.
11 SELINUXTYPE=targeted
- 仅列出 /etc/passwd 文件内的第 5-7 行
[root@localhost ~]# nl /etc/passwd | sed -n '5,7p'
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
数据的搜寻与显示
- 搜索 /etc/passwd有root关键字的行
[root@localhost ~]# nl /etc/passwd | sed -n '/root/p'
1 root:x:0:0:root:/root:/bin/bash
10 operator:x:11:0:operator:/root:/sbin/nologin
数据的搜寻并删除
- 删除/etc/passwd所有包含root的行,其他行输出
[root@localhost ~]# nl /etc/passwd | sed '/root/d'
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
数据的搜寻并执行命令
- 搜索/etc/passwd,找到root对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把bash替换为blueshell,再输出这行
[root@localhost ~]# nl /etc/passwd | sed -n '/root/{s/bash/blueshell/p;q}'
1 root:x:0:0:root:/root:/bin/blueshell
数据的搜寻并替换
除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的搜寻并取代
sed 's/要被取代的字串/新的字串/g'
案例:替换IP信息
先使用ifconfig命令查看当前的IP信息
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.88.10 netmask 255.255.255.0 broadcast 192.168.88.255
inet6 fe80::aee0:741:927e:335b prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:ae:c9:0f txqueuelen 1000 (Ethernet)
RX packets 4160 bytes 727537 (710.4 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2660 bytes 362687 (354.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- 取出IP地址所在的行
[root@localhost ~]# ifconfig | sed -n '/netmask/p'
inet 192.168.88.10 netmask 255.255.255.0 broadcast 192.168.88.255
inet 127.0.0.1 netmask 255.0.0.0
- 取出IP地址前后不需要的内容
[root@localhost ~]# ifconfig | sed -n '/netmask/p' | sed 's/^.*inet//g'
192.168.88.10 netmask 255.255.255.0 broadcast 192.168.88.255
127.0.0.1 netmask 255.0.0.0
[root@localhost ~]# ifconfig | sed -n '/netmask/p' | sed 's/^.*inet//g' | sed 's/netmask.*$//g'
192.168.88.10
127.0.0.1
- 取出第一个IP
[root@localhost ~]# ifconfig | sed -n '/netmask/p' | sed 's/^.*inet//g' | sed 's/netmask.*$//g'|sed -n '1p'
192.168.88.10
最终获得当前主机的IP地址
其他方式:
[root@localhost ~]# ip a|sed -n '/inet /p'| sed 's/^.*inet //g'|sed 's/\/.*$//g'| sed -n '2p'
192.168.88.10
多点编辑
一条sed命令,删除/etc/passwd第三行到末尾的数据,并把bash替换为blueshell
[root@localhost ~]# nl /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/'
1 root:x:0:0:root:/root:/bin/blueshell
2 bin:x:1:1:bin:/bin:/sbin/nologin
-e 表示多点编辑,第一个编辑命令删除/etc/passwd第三行到末尾的数据,第二条命令搜索bash替换为blueshell
直接修改文件内容(危险动作)
在sed的选项中加入-i,就是直接修改文件内容,实时生效,所以必须慎重使用。最好是先不加-i参数在测试环境中测试好了以后,在去修改文件本身
[root@localhost ~]# cat testfile
line one
line two
line three
line four
line five
[root@localhost ~]# sed -i 's/line/hello/g' testfile
[root@localhost ~]# cat testfile
hello one
hello two
hello three
hello four
hello five
文本三剑客之awk
(文本分析工具)
awk 是一种编程语言,它可以进行更加复杂的数据处理和分析。
使用方法
awk '{pattern + action}' {filenames}
其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
关注点:1、分隔符;2、具体的分析(定制化输出、数学与逻辑运算)
awk工作原理
执行 awk 时,它依次对/etc/passwd 中的每一行执行 print 命令
[root@localhost ~]# awk -F: '{print $0}' /etc/passwd
[root@localhost ~]# awk -F: '{print "用户名:" $1}' /etc/passwd
用户名:root
用户名:bin
用户名:daemon
用户名:adm
用户名:lp
用户名:sync
用户名:shutdown
用户名:halt
用户名:mail
用户名:operator
用户名:games
用户名:ftp
用户名:nobody
用户名:systemd-network
用户名:dbus
用户名:polkitd
用户名:sshd
用户名:postfix
用户名:chrony

[root@localhost ~]# awk -F":" '{print $1}' /etc/passwd
[root@localhost ~]# awk -F":" '{print $1 $3}' /etc/passwd
[root@localhost ~]# awk -F":" '{print $1 " " $3}' /etc/passwd
[root@localhost ~]# awk -F":" '{print "username:"$1 "\t tuid:" $3}' /etc/passwd
-F参数:指定分隔符,可指定一个或多个
print 后面做字符串的拼接
案例
查看文件内容
只查看test.txt文件(100行)内第20到第30行的内容(企业面试)
[root@localhost ~]# seq 100 > test.txt
[root@localhost ~]# awk '{if(NR>=20 && NR<=30) print $1}' test.txt
# NR为内置变量,表示行号,从1开始
20
21
22
23
24
25
26
27
28
29
30
过滤指定字符
已知文本内容如下:
[root@localhost ~]# cat testfile
I am nls, my qq is 12345678
从该文本中过滤出姓名和qq号,要求最后输出结果为:Name: QQ
[root@localhost ~]# awk -F '[ ,]' '{print "Name: " $3, "\nQQ: " $8}' testfile
Name: nls
QQ: 12345678
BEGIN 和 END 模块
- BEGIN 模块:
BEGIN模块是在 awk 开始处理输入数据之前执行的。- 它通常用于初始化一些变量或者打印一些提示信息。
- 比如在处理文件之前,先打印一行 "Processing the file..."。
- END 模块:
END模块是在 awk 处理完所有输入数据之后执行的。- 它通常用于输出一些最终的统计信息或者结果。
- 比如在处理完文件后,打印出总共处理了多少行数据。
案例一:统计当前系统中存在的账户数量
[root@localhost ~]# awk 'BEGIN {count=0;print "[start] user count is: "count}{count++;print $0} END{print "[end] user count is: " count}' /etc/passwd
[start] user count is: 0
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
[end] user count is: 19
在BEGIN中先定义一个初始的变量count=0,并且打印一段话,然后第二个{}中是具体执行的语句。最后在END中定义结束的操作,打印count的值.....
awk 'BEGIN {一开始执行的内容,只执行一遍}{反复执行的内容} END{最后执行的内容,仅一遍}' /etc/passwd
实例二:统计某个文件夹下的文件占用的字节数
[root@localhost ~]# ll | awk 'BEGIN {size=0} {size=size+$5} END{print "size is ",size}'
size is 2226
[root@localhost ~]# ll | awk 'BEGIN {size=0} {size=size+$5} END{print "size is ",size/1024/1024,"M"}'
size is 0.00212288 M
awk运算符
| 运算符 | 描述 |
|---|---|
| 赋值运算符 | |
| = += -= *= /= %= ^= **= | 赋值语句 |
| 逻辑运算符 | |
| ¦¦ | 逻辑或 |
| && | 逻辑与 |
| 正则运算符 | |
| ~ !~ | 匹配正则表达式和不匹配正则表达式 |
| 关系运算符 | |
| < <= > >= != == | 关系运算符 |
| 算数运算符 | |
| + - | 加,减 |
| * / & | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ -- | 增加或减少,作为前缀或后缀 |
| 其他运算符 | |
| $ | 字段引用 |
| 空格 | 字符串链接符 |
| ?: | 三目运算符 |
| ln | 数组中是否存在某键值 |
案例
- awk 赋值运算符:a+=5;等价于: a=a+5;其他同类
[root@localhost ~]# awk 'BEGIN{a=5;a+=5;print a}'
10
- awk逻辑运算符:判断表达式 a>2&&b>1为真还是为假,后面的表达式同理
[root@localhost ~]# awk 'BEGIN{a=1;b=2;print (a>2 && b>1,a=1 || b>1)}'
0 1
- awk正则运算符:
[root@localhost ~]# awk 'BEGIN{a="100testaa";if(a~/100/) {print "OK"}else {print "NO"}}'
OK
关系运算符:
如: > < 可以作为字符串比较,也可以用作数值比较,关键看操作数如果是字符串就会转换为字符串比较。两个都为数字 才转为数值比较。字符串比较:按照ascii码顺序比较。
# 如果是字符的话,就会按照ASCII码的顺序进行比较
[root@localhost ~]# awk 'BEGIN{a=11;if(a>=9){print"OK"}}'
OK
[root@localhost ~]# awk 'BEGIN{a;if(a>=b){print"OK"}}'
OK
算术运算符:
说明:所有用作算术运算符进行操作,操作数自动转为数值,所有非数值都变为0
[root@localhost ~]# awk 'BEGIN{a="b";print a++,++a}'
0 2
[root@localhost ~]# awk 'BEGIN{a="20b4";print a++,++a}'
20 22
这里的a++ , ++a与其他语言一样:a++是先赋值加++;++a是先++再赋值
- 三目运算符
?
[root@localhost ~]# awk 'BEGIN{a="b";print a=="b"?"ok":"err"}'
ok
[root@localhost ~]# awk 'BEGIN{a="b";print a=="c"?"ok":"err"}'
err
常用 awk 内置变量
| 变量名 | 属性 |
|---|---|
| $0 | 当前记录 |
| $1~$n | 当前记录的第n个字段 |
| FS | 输入字段分割符 默认是空格 |
| RS | 输入记录分割符 默认为换行符 |
| NF | 当前记录中的字段个数,就是有多少列 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFS | 输出字段分割符 默认也是空格 |
| ORS | 输出的记录分割符 默认为换行符 |
注:内置变量很多,参阅相关资料
- 字段分隔符 FS FS="\t+" 一个或多个 Tab 分隔
[root@localhost ~]# cat testfile
aa bb cc
[root@localhost ~]# awk 'BEGIN{FS="\t+"}{print $1,$2,$3}' testfile
aa bb cc
- FS="[[:space:]+]" 一个或多个空白空格,默认的,匹配到不符合的就停止
[root@localhost ~]# cat testfile
aa bb cc
[root@localhost ~]# awk 'BEGIN{FS="[[:space:]+]"}{print $1,$2,$3}' testfile
aa bb
[root@localhost ~]# awk -F [[:space:]+] '{print $1,$2}' testfile
aa bb
- FS="[" "]+" 以一个或多个空格分隔
[root@localhost ~]# cat testfile
aa bb cc
[root@localhost ~]# awk -F [" "]+ '{print $1,$2,$3}' testfile
aa bb cc
- 字段数量 NF:显示满足用:分割,并且有8个字段的
[root@localhost ~]# cat testfile
bin:x:1:1:bin:/bin:/sbin/nologin:888
bin:x:1:1:bin:/bin:/sbin/nologin
[root@localhost ~]# awk -F ":" 'NF==8{print $0}' testfile
bin:x:1:1:bin:/bin:/sbin/nologin:888
- 记录数量 NR (行号)
[root@localhost ~]# ifconfig ens33 | awk -F [" "]+ 'NR==2{print $3}'
192.168.88.10
- RS 记录分隔符变量
# 写法一(命令行)
[root@localhost ~]# awk 'BEGIN{FS=":";RS="\n"}{ print $1","$2","$3}' testfile
bin,x,1
bin,x,1
# 写法二(awk脚本)
[root@localhost ~]# cat awk.txt
#!/bin/awk
BEGIN {
FS=":"
RS="\n"
}
{
print $1","$2","$3
}
[root@localhost ~]# awk -f awk.txt testfile
bin,x,1
bin,x,1
- OFS:输出字段分隔符
[root@localhost ~]# awk 'BEGIN{FS=":";OFS="#"}{print $1,$2,$3}' testfile
bin#x#1
bin#x#1
- ORS:输出记录分隔符
[root@localhost ~]# awk 'BEGIN{FS=":";ORS="\n\n"}{print $1,$2,$3}' testfile
bin x 1
bin x 1
awk正则
| 元字符 | 功能 | 示例 | 解释 |
|---|---|---|---|
| ^ | 首航定位符 | /^root/ | 匹配所有以root开头的行 |
| $ | 行尾定位符 | /root$/ | 匹配所有以root结尾的行 |
| . | 匹配任意单个字符 | /r..t/ | 匹配字母r,然后两个任意字符,再以t结尾的行 |
| * | 匹配0个或多个前导字符(包括回车) | /a*ool/ | 匹配0个或多个a之后紧跟着ool的行,比如ool,aaaaool等 |
| + | 匹配1个或多个前导字符 | /a+b/ | ab, aaab |
| ? | 匹配0个或1个前导字符 | /a?b/ | b,ab |
| [] | 匹配指定字符组内的任意一个字符 | /^[abc]/ | 匹配以a或b或c开头的行 |
| [^] | 匹配不在指定字符组内任意一个字符 | /\^[\^abc]/ | 匹配不以字母a或b或c开头的行 |
| () | 子表达式组合 | /(rool)+/ | 表示一个或多个rool组合,当有一些字符需要组合时,使用括号括起来 |
| ¦ | 或者的意思 | /(root)\¦B/ | 匹配root或者B的行 |
| \ | 转义字符 | /a\/\// | 匹配a// |
| ~,!~ | 匹配,不匹配的条件语句 | $1~/root/ | 匹配第一个字段包含字符root的所有记录 |
| x{m}x{m,}x{m,n} | x重复m次x重复至少m次x重复至少m次,但是不超过n次 | /(root){3}//(root){3,}//(root){3,6}/ |
awk使用正则表达式
规则表达式
awk '/REG/{action} ' file,其中/REG/为正则表达式,可以将满足条件的记录送入到:action 进行处理
[root@localhost ~]# awk '/root/{print$0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost ~]# awk -F ":" '$5~/root/{print$0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# ifconfig ens33 | awk 'BEGIN{FS="[[:space:]:]+"} NR==2{print$3}'
192.168.88.10
布尔表达式
awk '布尔表达式{action}' file仅当对前面的布尔表达式求值为真时, awk 才执行代码块
[root@localhost ~]# awk -F: '$1=="root"{print$0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# awk -F: '($1=="root")&&($5=="root"){print$0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
awk的if、循环、和数组
if 条件判断
awk 提供了非常好的类似于 C 语言的 if 语句
{
if ($1=="foo"){
if ($2=="foo"){
print"uno"
}else{
print"one"
}
}elseif($1=="bar"){
print "two"
}else{
print"three"
}
}
还可以转换为:
{
if ( $0 !~ /matchme/ ) {
print $1 $3 $4
}
}
while 循环
awk 的 while 循环结构,它等同于相应的 C 语言 while 循环。 awk 还有"do...while"循环,它在代码块结尾处对条件求值,而不像标准 while 循环那样在开始处求值。
它类似于其它语言中的"repeat...until"循环。以下是一个示例:
do...while 示例:
{
count=1 do {
print "I get printed at least once no matter what"
} while ( count !=1 )
}
与一般的 while 循环不同,由于在代码块之后对条件求值, "do...while"循环永远都至少执行一次。换句话说,当第一次遇到普通 while 循环时,如果条件为假,将永远不执行该循环
for 循环
awk 允许创建 for 循环,它就象 while 循环,也等同于 C 语言的 for 循环:
for ( initial assignment; comparison; increment ) {
code block
}
以下是一个简短示例:
[root@localhost ~]# cat awk.txt
#!/bin/awk
BEGIN{for ( x=1; x<=4; x++ ) {
print "iteration", x
}}
[root@localhost ~]# awk -f awk.txt
iteration 1
iteration 2
iteration 3
iteration 4
break 和 continue
如同 C 语言一样, awk 提供了 break 和 continue 语句。使用这些语句可以更好地控制 awk 的循环结构。
break语句:
[root@localhost ~]# cat awk.txt
#!/bin/awk
BEGIN{
x=1
while(1) {
print "iteration",x
if ( x==10 ){
break
}
x++
}
}
[root@localhost ~]# awk -f awk.txt
iteration 1
iteration 2
iteration 3
iteration 4
iteration 5
iteration 6
iteration 7
iteration 8
iteration 9
iteration 10
continue 语句:
[root@localhost ~]# cat awk.txt
#!/bin/awk
BEGIN{
x=1
while (1) {
if ( x==4 ) {
x++
continue
}
print "iteration", x
if ( x>20 ) {
break
}
x++
}
}
[root@localhost ~]# awk -f awk.txt
iteration 1
iteration 2
iteration 3
iteration 5
iteration 6
iteration 7
iteration 8
iteration 9
iteration 10
iteration 11
iteration 12
iteration 13
iteration 14
iteration 15
iteration 16
iteration 17
iteration 18
iteration 19
iteration 20
iteration 21
数组
AWK 中的数组都是关联数组,数字索引也会转变为字符串索引
在awk中,数组叫关联数组,与我们在其它编程语言中的数组有很大的区别。关联数组,简单来说,类似于python语言中的dict、java语言中的map,其下标不再局限于数值型,而可以是字符串,即下标为key,value=array[key]。既然为key,那其下标也不再是有序的啦。
#!/bin/awk
BEGIN{
cities[1]="beijing"
cities[2]="shanghai"
cities["three"]="guangzhou"
for( c in cities) {
print cities[c]
}
print cities[1]
print cities["1"]
print cities["three"]
}
awk -f awk.txt <filename>
用 awk 中查看服务器连接状态并汇总
[root@localhost ~]# netstat -an|awk '/^tcp/{++s[$NF]}END{for(a in s)print a,s[a]}'
LISTEN 4
ESTABLISHED 2
常用字符串函数
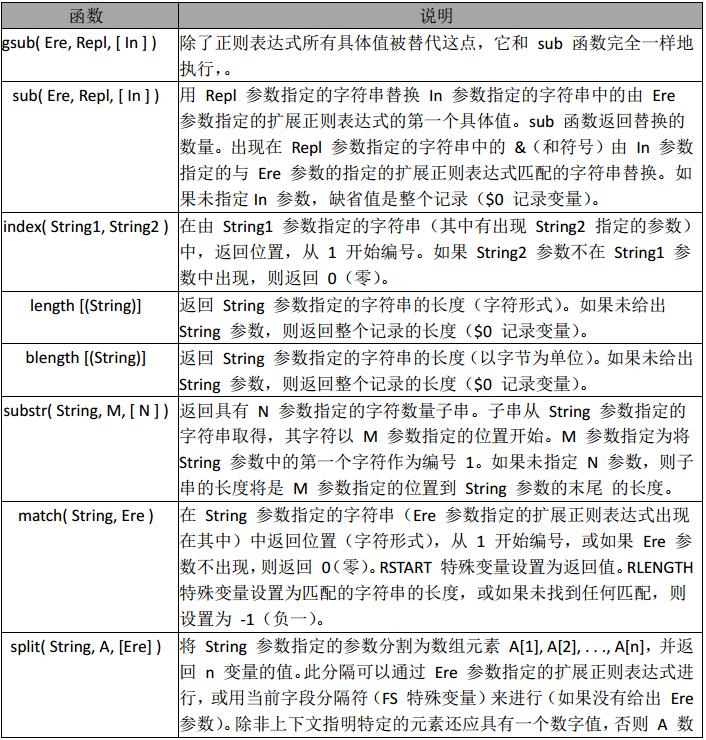
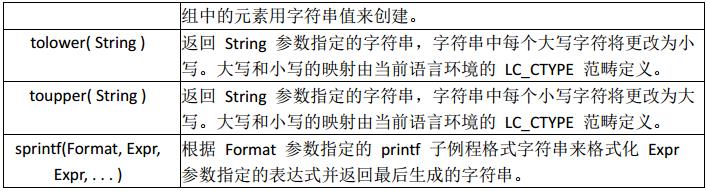
字符串函数的应用:
- 在 info 中查找满足正则表达式, /[0-9]+/ 用”!”替换,并且替换后的值,赋值给 info
[root@localhost ~]# awk 'BEGIN{info="this is a test2010test!";gsub(/[0-9]+/,"!",info);print info}'
this is a test!test!
- 如果查找到数字则匹配成功返回 ok,否则失败,返回未找到
[root@localhost ~]# awk 'BEGIN{info="this is a test2010test!";print index(info,"test")?"ok":"no found";}'
ok
- 从第 4 个 字符开始,截取 10 个长度字符串
[root@localhost ~]# awk 'BEGIN{info="this is a test2010test!";print substr(info,4,10);}'
s is a tes
- 分割 info,动态创建数组 tA,awk for …in 循环,是一个无序的循环。 并不是从数组下标1…n 开始
[root@localhost ~]# awk 'BEGIN{info="this is a test";split(info,tA," ");print length(tA);for(k in tA){print k,tA[k];}}'
4
4 test
1 this
2 is
3 a