Python基本数据结构
列表(List)
列表是一个有序的可变集合,可以存储不同类型的元素。列表相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据。而且列表是有序的,有索引值,可切片,方便取值。
定义列表
fruits = ["apple", "banana", "cherry"]
print(fruits)
# Output:
['apple', 'banana', 'cherry']
增加元素
# 1. 按照索引的位置去增加
fruits.insert(1, "kiwi")
# 2. 在最末尾添加
fruits.append("orange")
# 3. 用迭代的方式去添加
fruits.extend(['a','b','c'])
# 可以立即为再传递一个List进去,然后依次添加到末尾,而append会把括号里的当成一个整体添加到末尾
# Output:
['apple', 'kiwi', 'banana', 'cherry', 'orange', 'a', 'b', 'c']
删除元素
# 1. 删除制定的具体元素
fruits.remove("cherry")
# 2. 按照索引位置去删除
fruits.pop() # 默认是删除最后一个,可以加上索引。并且有返回值,返回值为删除的元素
fruits.pop(1)
# 3. 使用切片范围删除
del fruits[1:3] # 没有返回值
# 4. 清空列表
fruits.clear()
# 5. 删除列表
del fruits
# clear是清空列表的内容,变成一个空列表,而del是删除列表本身,后续无法再次调用...
# Output:
['apple', 'banana', 'cherry']
['apple', 'kiwi', 'banana', 'cherry', 'orange', 'a', 'b', 'c']
[]
修改元素
# 1. 按照索引修改某个元素的值
fruits = ["apple", "banana", "cherry"]
fruits[1] = "orange"
print(fruits)
# Output:
['apple', 'orange', 'cherry']
# 2. 按照切片范围修改
fruits[0:2] = ['kiwi','orange']
print(fruits)
# Output:
['kiwi', 'orange', 'cherry']
查找元素
# 1. index(element):返回元素的索引
fruits = ["apple", "banana", "cherry"]
index_of_apple = fruits.index("apple")
print(index_of_apple)
# Output:
0
# 2. count(element):返回元素出现的次数
count_of_cherry = fruits.count("cherry")
print(count_of_cherry)
# Output:
1
列表的切片
切片是按照一定的索引规律分割列表从而组成一个新的列表,类似与我们字符串中讲到的切片
li = [1,2,4,5,4,2,4]
sub_li = li[2:5]
print(sub_li)
# Output:
[4, 5, 4]
其他操作
li = [1,2,4,5,4,2,4]
# 1. 统计某个元素出现的次数
print (li.count(4))
# 2. 从列表中找出某个值第一个匹配项的索引位置
print (li.index(2))
# 3. 对列表进行排序
li.sort()
print(li)
# 4. 将列表中的元素反向存放
li.reverse()
print (li)
# Output:
3
1
[1, 2, 2, 4, 4, 4, 5]
[5, 4, 4, 4, 2, 2, 1]
元组(Tuple)
有序的不可变集合,也被被称为只读列表,即数据可以被查询,但不能被修改。
定义元组
tuple = (1,2,3,'a','b','c')
print(tuple)
print(tuple[1])
# 可以删除元素吗?
tuple.pop()
# Output:
AttributeError: 'tuple' object has no attribute 'pop'
可变元组
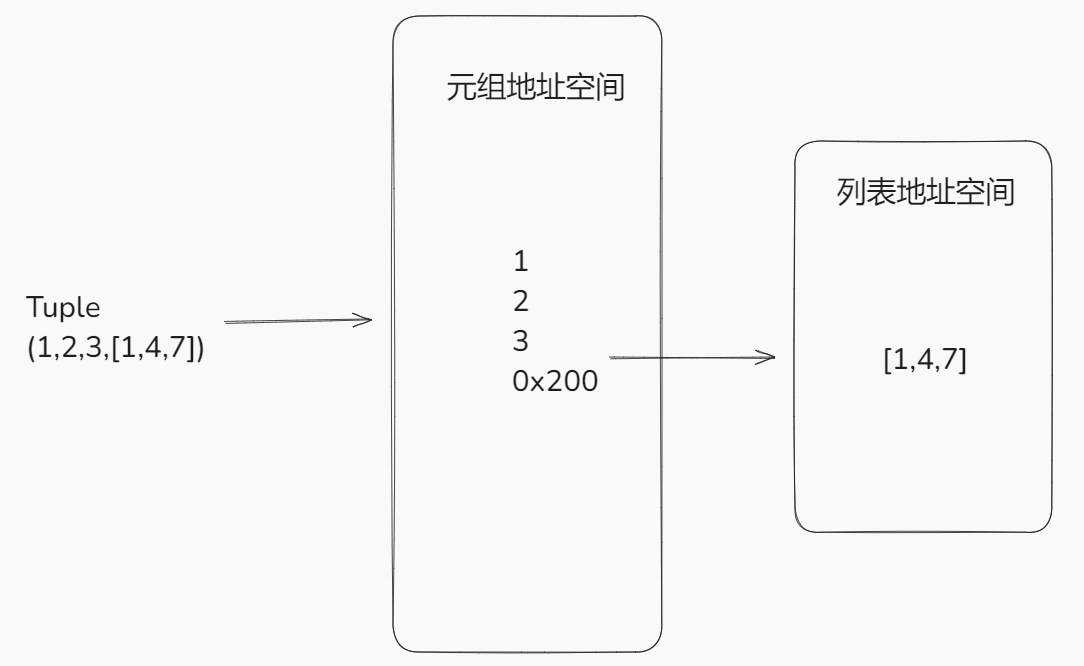
tuple其实不可变的是地址空间,如果地址空间里存的是可变的数据类型的话,比如列表就是可变的
tuple = (1, 2, 3, [1, 4, 7])
print(tuple)
tuple[3][2] = 100
print(tuple)
# Output:
(1, 2, 3, [1, 4, 7])
(1, 2, 3, [1, 4, 100])
在元组tuple中,包含一个list类型的数据,由于list是可以变的,所以我们可以更改元组里list的值,但是元组本身的地址空间是不变的。
字典(Dict)
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
不过在Python 3.6版本以后,字典会保留插入顺序,变成有序数据结构。
而且键是具有唯一性的,每个键只能出现一次,但是值没有限制,在一个字典中可以出现多个相同的值。
定义字典
dic = {'name':'nls','age':18,'job':'teacher'}
print(dic)
print(dic['name'])
print(dic['age'])
print(dic['job'])
# Output:
{'name': 'nls', 'age': 18, 'job': 'teacher'}
nls
18
teacher
增加键值
dic = {'name':'nls','age':18,'job':'teacher'}
# 1. 直接通过键值对来增加
dic['hobby'] = 'study' # 如果键已经存在,那么就会替换原来的值
print(dic)
# Output: {'name': 'nls', 'age': 18, 'job': 'teacher', 'hobby': 'study'}
# 2. 在字典中添加键值对时,如果指定的键已经存在则不做任何操作,如果原字典中不存在指定的键值对,则会添加。
dic.setdefault('name','牛老师')
dic.setdefault('gender','男')
print(dic)
# Output:
{'name': 'nls', 'age': 18, 'job': 'teacher', 'hobby': 'study', 'gender': '男'}
删除键值
dic = {'name':'nls','age':18,'job':'teacher'}
# 1. 删除指定的键,并且返回对应的值
name = dic.pop('job')
hobby = dic.pop('hobby','查无此项') # 可以在后面加上一个异常处理,如果key不存在,就输出后面的内容
print(dic)
print(name)
print(hobby)
# Output:
{'name': 'nls', 'age': 18}
teacher
查无此项
# 2. 使用del关键字删除指定的键值对
del dic['name']
# 3. 删除最后插入的键值对
dic_pop = dic.popitem()
print(dic_pop)
# 4. 清空字典
dic.clear()
print(dic)
# Output: {}
修改键值
dic = {'name':'nls','age':18,'job':'teacher'}
dic['age'] = 25
print(dic)
# Output:
{'name': 'nls', 'age': 25, 'job': 'teacher'}
查找键值
dic = {'name':'nls','age':18,'job':'teacher'}
# 1. 直接通过键名获取,如果不存在会报错
value = dic['name']
print(value)
# 2. 使用get方法获取键值,若不存在则返回 None,可以自定义异常返回值
value = dic.get('job','查无此项')
print(value)
# Output:
nls
teacher
# 3. IN关键字,存在返回True,反之False
exists = "name" in dic
print(exists)
# Output:
True
其他操作
dic = {'name':'nls','age':18,"phone":['1888888888','0511-10101010']}
# 字典里面的value也可以是容器类型的数据,比如列表,字典等等...但是key必须是不可变的
print(dic)
# 1. 对键和值进行迭代操作
for i in dic.items():
# 将键和值作为元祖列出
print(i)
for i in dic:
# 只迭代键
print(i)
# Output:
('name', 'nls')
('age', 18)
('phone', ['1888888888', '0511-10101010'])
name
age
phone
# 2. 使用keys()和values()方法获取键值
keys = dic.keys()
print(keys,type(keys))
value = dic.values()
print(value,type(value))
# Output:
dict_keys(['name', 'age', 'phone']) <class 'dict_keys'>
dict_values(['nls', 18, ['1888888888', '0511-10101010']]) <class 'dict_values'>
集合(Set)
集合是无序的,不重复,确定性的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
- 去重,把一个列表变成集合,就自动去重了。
- 关系测试,测试两组数据之前的交集、差集、并集等关系。
定义集合
set1 = {1,2,3,'a','b','c'} # 推荐方法
set2 = set({1,2,3})
print(set1, set2)
# Output:
{1, 2, 3, 'b', 'c', 'a'} {1, 2, 3}
增加元素
set1 = {1,2,3,'a','b','c'}
# 1. 使用add()方法为集合增加元素
set1.add('d')
print(set1)
# Output:
{'a', 1, 2, 3, 'c', 'd', 'b'}
# 2. 使用update()方法迭代的去增加
set1.update('e','f')
# update接收的参数应该是可迭代的数据类型,比如字符串、元组、列表、集合、字典。这些都可以向集合中添加元素,但是整型、浮点型不可以
set1.update([4,5,6])
print(set1)
# Output:
{1, 2, 3, 4, 5, 6, 'a', 'd', 'b', 'c', 'f', 'e'}
删除元素
set1 = {1,2,3,'a','b','c'}
# 1. 使用remove()方法删除元素
set1.remove('a')
print(set1)
# 2. 随机删除某个元素
set1.pop()
print(set1)
# Output:
{1, 2, 3, 'c', 'b'}
{2, 3, 'c', 'b'}
# 3. 删除集合本身
del set1
查找元素
set1 = {1,2,3,'a','b','c'}
exists = "a" in set1 # True
print(exists)
关系测试
交集(& 或者 intersection)
取出两个集合共有的元素
set1 = {1,2,3,4,5}
set2 = {3,4,5,6,7}
print(set1 & set2)
print(set1.intersection(set2))
# Output:
{3, 4, 5}
{3, 4, 5}
反交集(^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {3,4,5,6,7}
print(set1 ^ set2)
print(set1.symmetric_difference(set2))
# Output:
{1, 2, 6, 7}
{1, 2, 6, 7}
并集(| 或者 union)
合并两个集合的所有元素
set1 = {1,2,3,4,5}
set2 = {3,4,5,6,7}
print(set1 | set2)
print(set2.union(set1))
# Output:
{1, 2, 3, 4, 5, 6, 7}
{1, 2, 3, 4, 5, 6, 7}
差集(- 或者 difference)
第一个集合去除二者共有的元素
set1 = {1,2,3,4,5}
set2 = {3,4,5,6,7}
print(set1 - set2)
print(set1.difference(set2))
# Output:
{1, 2}
{1, 2}
子集与超集
当一共集合的所有元素都在另一个集合里,则称这个集合是另一个集合的子集,另一个集合是这个集合的超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集
不可变集合
set1 = {1,2,3,4,5,6}
set2 = frozenset(set1)
print(set2,type(set2))
set2.add(7) # 不可以修改,会报错
# Output:
AttributeError: 'frozenset' object has no attribute 'add'
数据结构的总结
| 数据结构 | 描述 | 特性 | 常见操作 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| 列表 (List) | 有序的可变集合 | 有序、可变、支持重复 | 添加、删除、修改、查找 | 需要维护元素顺序的场景,如队列、栈的实现 | 灵活性高,支持多种操作 | 查询复杂度为 O(n),插入和删除性能较差 |
| 元组 (Tuple) | 有序的不可变集合 | 有序、不可变、支持重复 | 查找 | 元素不需要修改的场景,如函数参数、字典键 | 更节省内存,速度较快 | 不支持修改 |
| 集合 (Set) | 无序的可变集合 | 无序、可变、不支持重复 | 添加、删除、查找 | 需要去重和快速查找的场景,如集合运算 | 快速查找和去重 | 不支持索引,元素无序 |
| 字典 (Dictionary) | 有序的键值对集合 | 有序、可变、键唯一 | 添加、删除、修改、查找 | 需要快速查找和存储键值对的场景,如缓存 | 快速查找(O(1) 平均复杂度) | 键必须是不可变类型,内存开销较大 |
| 字符串 (String) | 字符的序列 | 不可变 | 查找、切片、替换 | 文本处理 | 易于使用,内置丰富的方法 | 不可修改,性能较低 |
流程控制
判断语句(if)
语法:
if 条件:
满足条件后要执行的代码
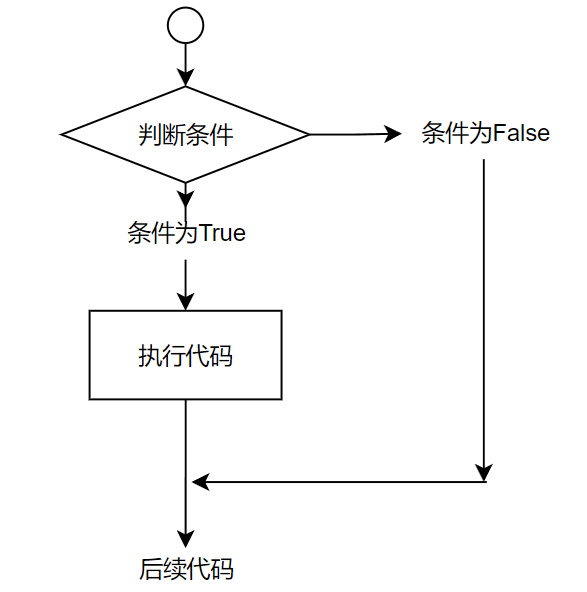
单分支判断
# 提示用户输入年龄
age = int(input("请输入你的年龄:"))
# 单分支判断
if age >= 18:
print("已经成年,可以去网吧上网了")
print("欢迎来到Eagles网吧")
print("你还没成年,要好好学习")
双分支判断
"""
if 条件:
满足条件执行代码
else:
if条件不满足就走这段
"""
# 提示用户输入年龄
age = int(input("请输入你的年龄:"))
# 单分支判断
if age >= 18:
print("已经成年,可以去网吧上网了")
print("欢迎来到Eagles网吧")
else:
print("你还没成年,要好好学习")
多分支判断
if 条件:
满足条件执行代码
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
else:
上面所有的条件不满足就走这段
# 成绩判断程序
# 提示用户输入成绩
score = int(input("请输入成绩(0-100):"))
# 多分支判断成绩
if score >= 90 and score <= 100:
print("优秀")
elif score >= 60 and score < 90:
print("良好")
elif score >= 0 and score < 60:
print("不及格")
else:
print("输入错误,请输入0到100之间的成绩。")
循环语句-while
语法:
while 条件:
循环体
# 循环条件可以直接是True/False或者1/0,也可以是某个语句...
如果条件为真,那么循环体则执行 如果条件为假,那么循环体不执行
示例:猜数字小游戏
print('猜数字游戏开始')
num = 54
while True:
guess = int(input("您猜数字是什么?(输入0-100的数字):"))
if guess < num:
print("您猜小了")
continue
elif guess > num:
print("您猜大了")
continue
break
print("您猜对了!")
# Output:
猜数字游戏开始
您猜数字是什么?(输入0-100的数字):10
您猜小了
您猜数字是什么?(输入0-100的数字):50
您猜小了
您猜数字是什么?(输入0-100的数字):60
您猜大了
您猜数字是什么?(输入0-100的数字):54
您猜对了!
循环终止语句
break
用于完全结束一个循环,跳出循环体执行循环后面的语句
continue
和 break 有点类似,区别在于 continue 只是终止本次循环,接着还执行后面的循环,break 则完全终止循环
while...else结构
while 后面的 else 作用是指,当 while 循环正常执行完,中间没有被 break 中止的话,就会执行 else 后面的语句
- 语法:
while condition:
# 循环体
if some_condition:
break
else:
# 循环正常结束时执行的代码
- 示例:
# 寻找素数的示例
num = 10
i = 2
while i < num:
if num % i == 0:
print(f"{num} 不是素数,因为它可以被 {i} 整除。")
break
i += 1
else:
print(f"{num} 是一个素数!")
循环语句-for
for循环:用户按照顺序循环可迭代对象的内容
语法:
for variable in iterable:
# 循环体
# 执行的代码
遍历列表
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
# Output:
apple
banana
cherry
遍历字符串
word = "helloworld"
for letter in word:
print(letter)
# Output:
h
e
l
l
o
w
o
r
l
d
enumerate
enumerate:枚举,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。
li = ['甲','乙','丙','丁']
for i in enumerate(li):
print(i)
for index,value in enumerate(li):
print(index,value)
for index,value in enumerate(li,100): #从哪个数字开始索引
print(index,value)
# Output:
(0, '甲')
(1, '乙')
(2, '丙')
(3, '丁')
0 甲
1 乙
2 丙
3 丁
100 甲
101 乙
102 丙
103 丁
range
指定范围,生成指定数字
for i in range(1,10):
print(i)
for i in range(1,10,2): # 步长
print(i)
for i in range(10,1,-2): # 反向步长
print(i)
小游戏案例
石头简单布
import random
# random产生随机值或者从给定值中随机选择
# 可选择的选项
options = ["石头", "剪子", "布"]
print("欢迎来到石头剪子布游戏!")
print("请从以下选项中选择:")
for i, option in enumerate(options):
print(f"{i + 1}. {option}")
# 玩家选择
player_choice = int(input("请输入你的选择(1-3):")) - 1
# 计算机随机选择
computer_choice = random.randint(0, 2)
print(f"\n你选择了:{options[player_choice]}")
print(f"计算机选择了:{options[computer_choice]}")
# 判断胜负
if player_choice == computer_choice:
print("平局!")
elif (player_choice == 0 and computer_choice == 1) or \
(player_choice == 1 and computer_choice == 2) or \
(player_choice == 2 and computer_choice == 0):
print("你赢了!🎉")
else:
print("你输了!😢")
课后作业
完善猜数字小游戏
生成一个随机数
猜错3次了以后,程序自动退出...
完善石头剪刀布游戏
- 更新游戏规则,实现三局两胜制
- 胜利条件:
- 2:1
- 3:0