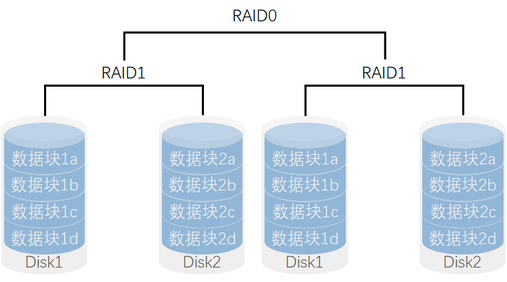
RAID 0
将数据条带化,读写性能*N,但是挂了一块盘会导致所有数据丢失。
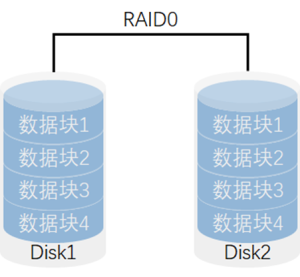
RAID 1
将数据镜像化,读写性能*1,挂了一块盘有备份。
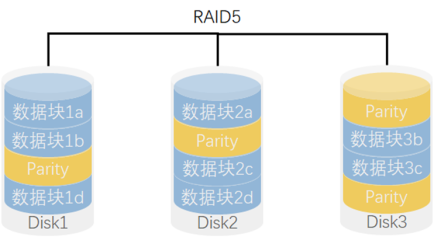
RAID 5
写性能1,读性能\(N-1)
RAID5的核心思想是使用奇偶校验信息来提供数据的冗余备份。当其中一个硬盘驱动器发生故障时,剩余的硬盘驱动器可以通过计算奇偶校验信息来恢复丢失的数据。这种方式既提供了数据冗余和容错能力,又降低了整体存储成本。
RAID 10
先做数据镜像,再做数据条带
读写性能*N(N为RAID0的硬盘数,此例为2),不能同时坏数据块1a与2a
部署磁盘阵列
软件阵列vs硬件阵列
硬件阵列额外花钱,而且需要缓存。在大容量文件存储的场景下,硬阵列用处不大,因为缓存几乎无用。
mdadm命令
常用参数以及作用
| 参数 | 作用 |
|---|---|
| -a | 检测设备名称 |
| -n | 指定设备数量 |
| -l | 指定RAID级别 |
| -C | 创建 |
| -v | 显示过程 |
| -f | 模拟设备损坏 |
| -r | 移除设备 |
| -Q | 查看摘要信息 |
| -D | 查看详细信息 |
| -S | 停止RAID磁盘阵列 |
| -x | 备份盘数量 |
[root@localhost ~]# yum -y install mdadm
[root@localhost ~]# mdadm -Cv /dev/md0 -a yes -n 4 -l 10 /dev/sdb /dev/sdc /dev/sdd /dev/sde
mdadm: layout defaults to n2
mdadm: layout defaults to n2
mdadm: chunk size defaults to 512K
mdadm: size set to 20954112K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
把制作好的RAID磁盘阵列格式化为ext4格式
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=128 blocks, Stripe width=256 blocks
2621440 inodes, 10477056 blocks
523852 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2157969408
320 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
创建挂载点然后把硬盘设备进行挂载操作
[root@localhost ~]# mkdir /mnt/RAID
[root@localhost ~]# mount /dev/md0 /mnt/RAID
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 17G 1.1G 16G 7% /
devtmpfs 898M 0 898M 0% /dev
tmpfs 910M 0 910M 0% /dev/shm
tmpfs 910M 9.6M 901M 2% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/sda1 1014M 146M 869M 15% /boot
tmpfs 182M 0 182M 0% /run/user/0
/dev/md0 40G 49M 38G 1% /RAID
查看/dev/md0磁盘阵列的详细信息,并把挂载信息写入到配置文件中,使其永久生效。
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Mon Apr 15 17:43:04 2019
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Mon Apr 15 17:44:14 2019
State : active, resyncing
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Resync Status : 66% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 9b664b1c:ab2b2fb6:6a00adf6:6167ad51
Events : 15
Number Major Minor RaidDevice State
0 8 16 0 active sync set-A /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
[root@localhost ~]# echo "/dev/md0 /RAID ext4 defaults 0 0" >> /etc/fstab
测试磁盘性能:
# 从zero里面取无穷无尽的文件,写入file文件,每次取256M,取4次。
# 因为先写内存,再到硬盘,防止内存过载。
[root@localhost ~]# dd < /dev/zero > file bs=256M count=4
记录了4+0 的读入
记录了4+0 的写出
1073741824字节(1.1 GB)已复制,2.21844 秒,484 MB/秒
关闭部署好的磁盘阵列
关闭RAID阵列
[root@localhost ~]# umount /dev/md0 /mnt/RAID/
# 先取消在文件系统中的挂载
[root@localhost ~]# mdadm -S /dev/md0
#必须清除成员磁盘当中阵列的超级块信息,这一步很重要!否则开机会重新做RAID
[root@localhost ~]# mdadm --zero-superblock /dev/sd[b-e]
#取消开机自动挂载,干掉那一行
[root@localhost ~]# vim /etc/fstab
损坏磁盘阵列及修复
在确认有一块物理硬盘设备出现损坏而不能继续正常使用后,应该使用mdadm命令将其移除,然后查看RAID磁盘阵列的状态,可以发现状态已经改变。
[root@localhost ~]# mdadm /dev/md0 -f /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Apr 18 09:25:38 2019
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Apr 18 09:28:24 2019
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 1
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 09c273ff:77fa1bc2:84a934f1:b924fa6e
Events : 27
Number Major Minor RaidDevice State
- 0 0 0 removed
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
0 8 16 - faulty /dev/sdb
在RAID 10级别的磁盘阵列中,当RAID 1磁盘阵列中存在一个故障盘时并不影响RAID 10磁盘阵列的使用。当购买了新的硬盘设备后再使用mdadm命令来予以替换即可,在此期间我们可以在/RAID目录中正常地创建或删除文件。由于我们是在虚拟机中模拟硬盘,所以先重启系统,然后再把新的硬盘添加到RAID磁盘阵列中。
[root@localhost ~]# umount /mnt/RAID/
#有时候失败,告诉设备忙,-f参数都没用
#用fuser -v -n file /mnt/RAID/查看谁占用文件详细,包括进程号
#用fuser -v -n tcp 22命令查看tcp22号端口占用的进程与用户
#用fuser -mk /mnt/RAID/命令杀死所有占用该文件的进程
#先热移除sdb
[root@localhost ~]# mdadm /dev/md0 -r /dev/sdb
#再加上sdb
[root@localhost ~]# mdadm /dev/md0 -a /dev/sdb
mdadm: added /dev/sdb
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Apr 18 09:25:38 2019
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Apr 18 09:34:14 2019
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 30% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 09c273ff:77fa1bc2:84a934f1:b924fa6e
Events : 47
Number Major Minor RaidDevice State
4 8 16 0 spare rebuilding /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
[root@localhost ~]# echo "/dev/md0 /mnt/RAID ext4 defaults 0 0" >> /etc/fstab
[root@localhost ~]# mount -a
# 有时候重新加sdb没用,只能删了阵列重新组,数据会全丢失
#[root@localhost ~]# umount /mnt/RAID/
#[root@localhost ~]# mdadm -S /dev/md0
#[root@localhost ~]# mdadm -Cv /dev/md0 -a yes -n 4 -l 10 /dev/sdb /dev/sdc /dev/sdd /dev/sde
#[root@localhost ~]# mkfs.ext4 /dev/md0
磁盘阵列+备份盘
为了避免多个实验之间相互发生冲突,我们需要保证每个实验的相对独立性,为此需要大家自行将虚拟机还原到初始状态。
部署RAID 5磁盘阵列时,至少需要用到3块硬盘,还需要再加一块备份硬盘,所以总计需要在虚拟机中模拟4块硬盘设备
现在创建一个RAID 5磁盘阵列+备份盘。在下面的命令中,参数-n 3代表创建这个RAID 5磁盘阵列所需的硬盘数,参数-l 5代表RAID的级别,而参数-x 1则代表有一块备份盘。当查看/dev/md0(即RAID 5磁盘阵列的名称)磁盘阵列的时候就能看到有一块备份盘在等待中了。
[root@localhost ~]# mdadm -Cv /dev/md0 -n 3 -l 5 -x 1 /dev/sdb /dev/sdc /dev/sdd /dev/sde
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: /dev/sdb appears to be part of a raid array:
level=raid10 devices=4 ctime=Thu Apr 18 09:25:38 2019
mdadm: /dev/sdc appears to be part of a raid array:
level=raid10 devices=4 ctime=Thu Apr 18 09:25:38 2019
mdadm: /dev/sdd appears to be part of a raid array:
level=raid10 devices=4 ctime=Thu Apr 18 09:25:38 2019
mdadm: /dev/sde appears to be part of a raid array:
level=raid10 devices=4 ctime=Thu Apr 18 09:25:38 2019
mdadm: size set to 20954112K
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Apr 18 09:39:26 2019
Raid Level : raid5
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Apr 18 09:40:28 2019
State : clean
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : f72d4ba2:1460fae8:9f00ce1f:1fa2df5e
Events : 18
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
3 8 64 - spare /dev/sde
将部署好的RAID 5磁盘阵列格式化为ext4文件格式,然后挂载到目录上,之后就可以使用了。
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=128 blocks, Stripe width=256 blocks
2621440 inodes, 10477056 blocks
523852 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2157969408
320 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# echo "/dev/md0 /RAID ext4 defaults 0 0" >> /etc/fstab
[root@localhost ~]# mkdir /mnt/RAID
[root@localhost ~]# mount -a
把硬盘设备/dev/sdb移出磁盘阵列,然后迅速查看/dev/md0磁盘阵列的状态
[root@localhost ~]# mdadm /dev/md0 -f /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
# /dev/sde由原来的spare顶上来变成spare-building
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Apr 18 09:39:26 2019
Raid Level : raid5
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Apr 18 09:51:48 2019
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 1
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 40% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : f72d4ba2:1460fae8:9f00ce1f:1fa2df5e
Events : 26
Number Major Minor RaidDevice State
3 8 64 0 spare rebuilding /dev/sde
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
0 8 16 - faulty /dev/sdb
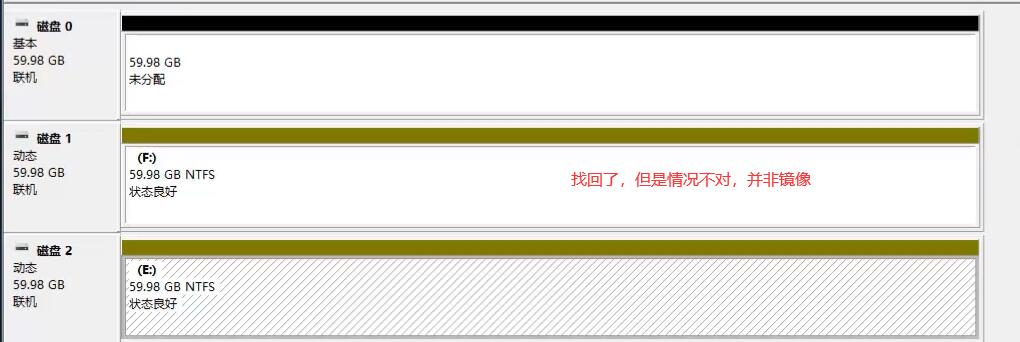
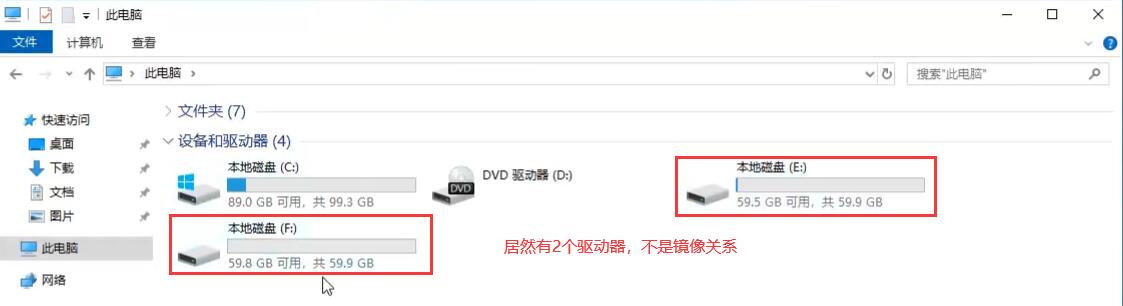
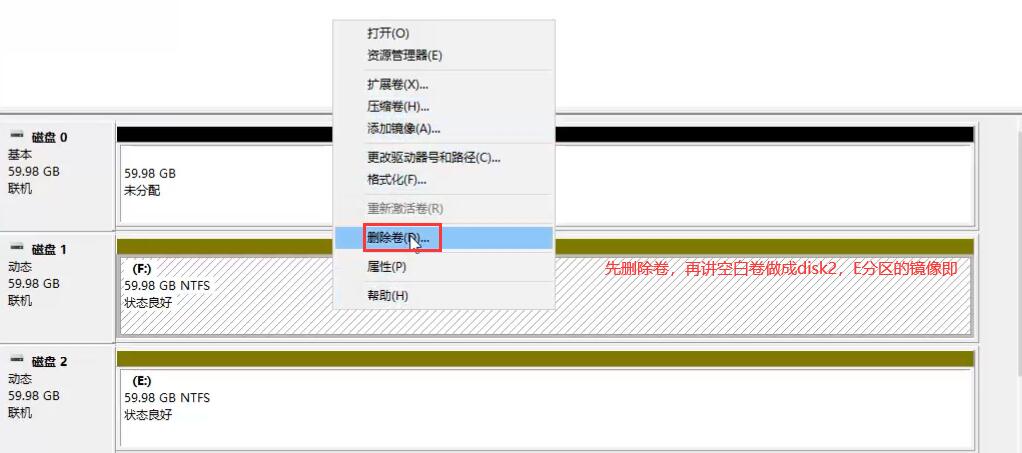
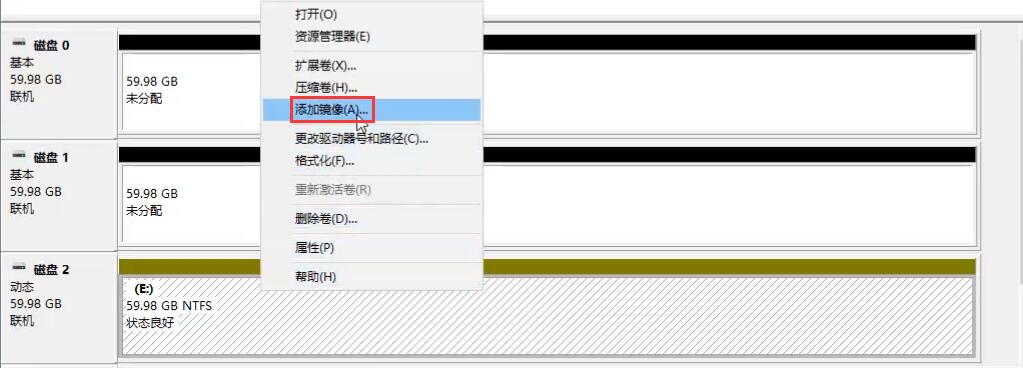
微软系统的做法:
跨区卷即LVM
带区卷(RAID0):
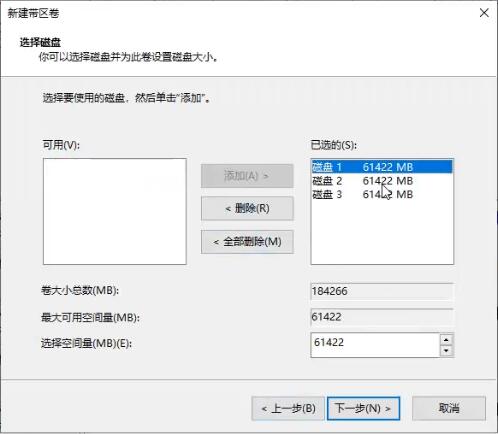
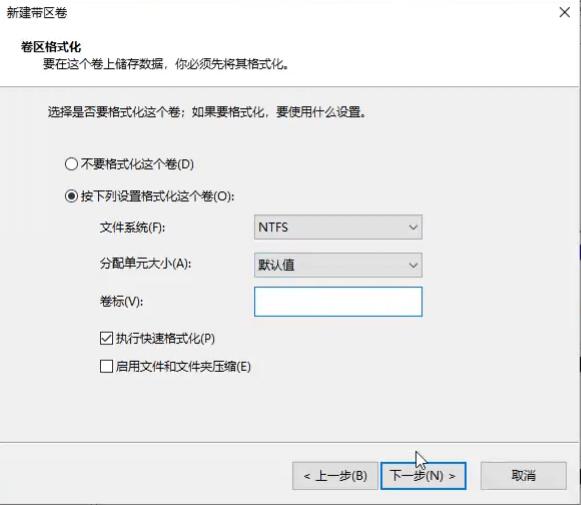
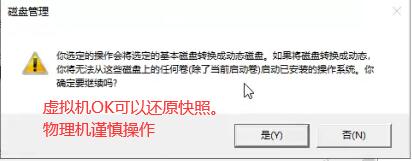
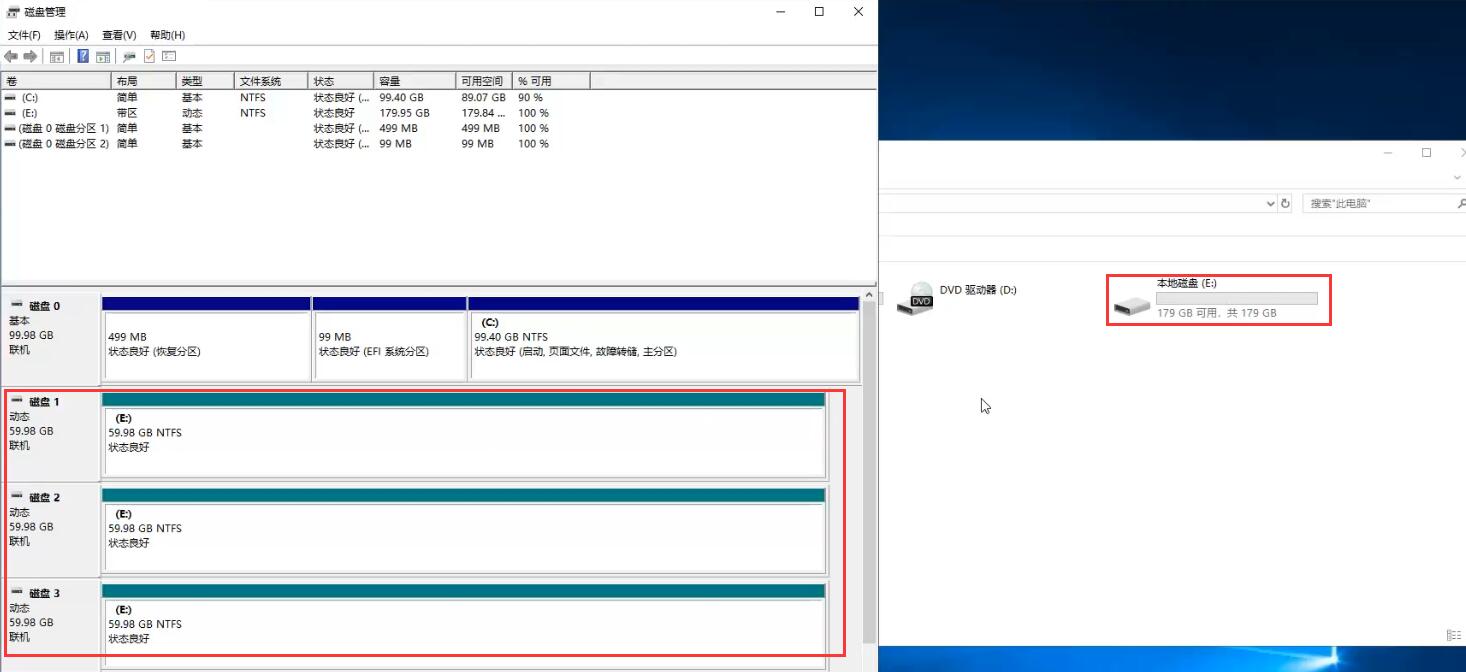
镜像卷(RAID1):
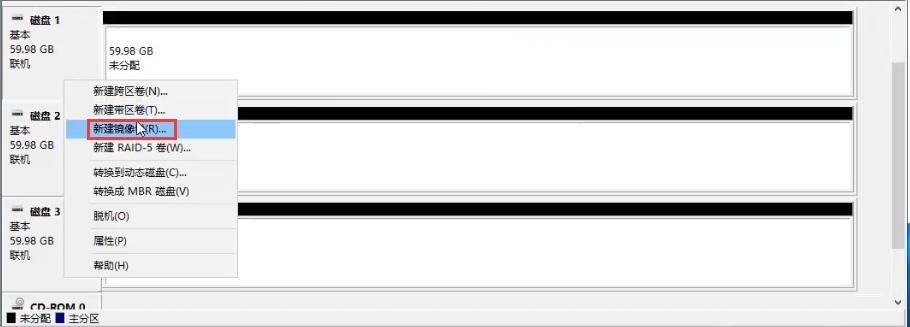
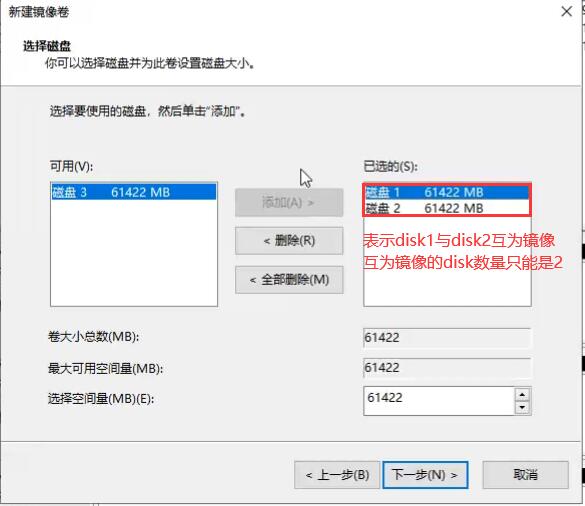
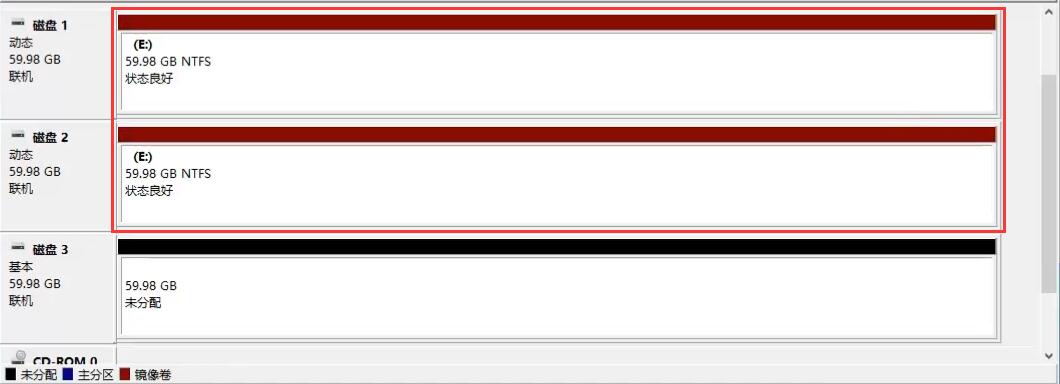
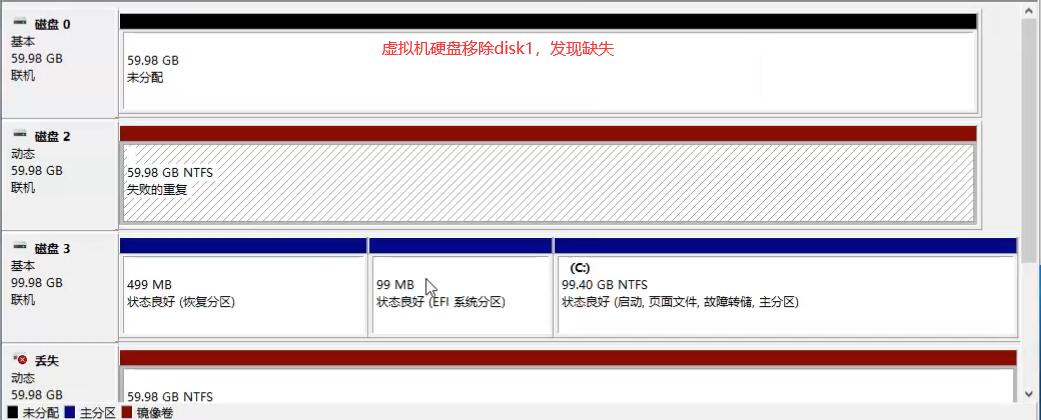
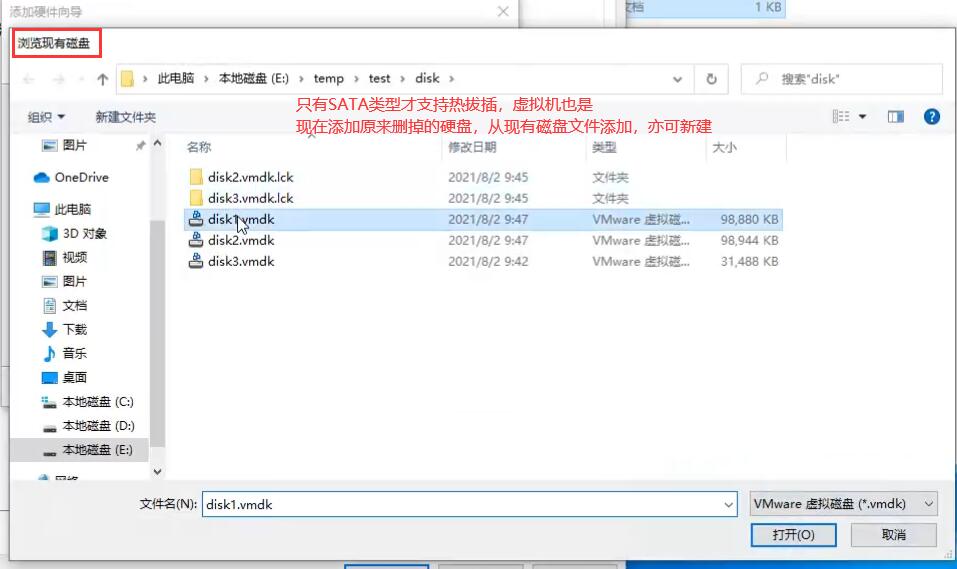
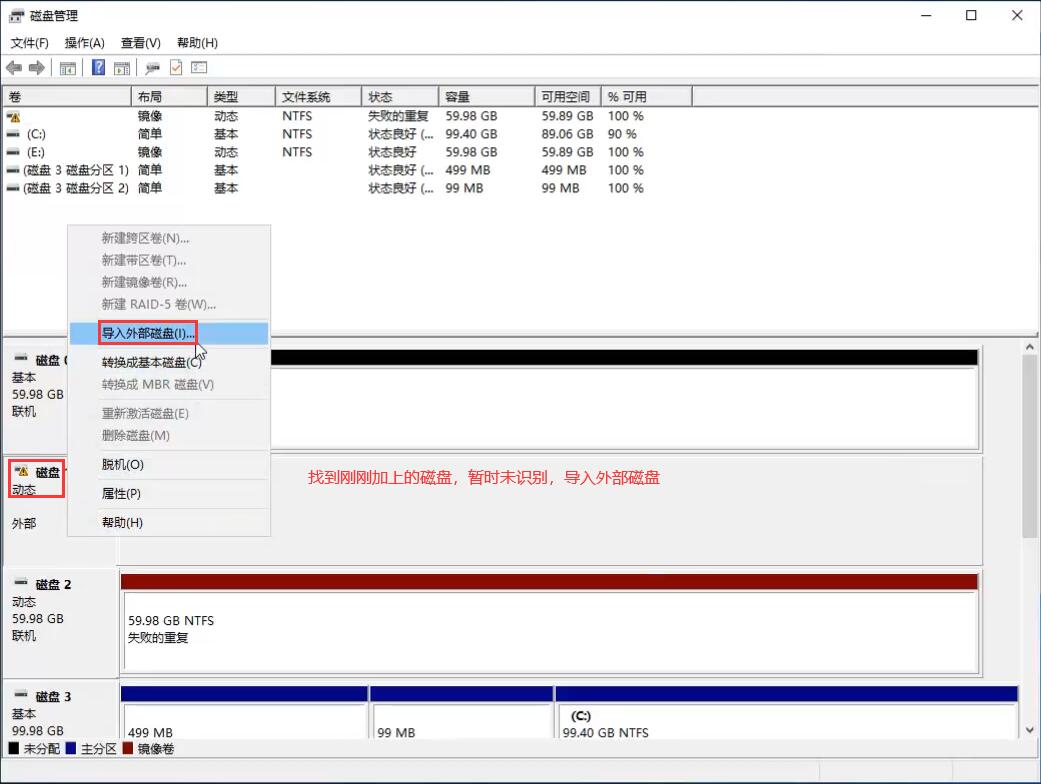
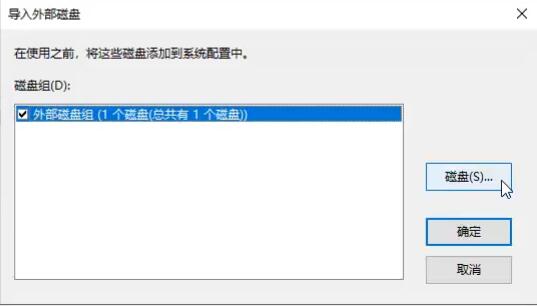
此时拔出硬盘1